בינה מלאכותית היא אחת הטכנולוגיות הצומחות ביותר תוך שימוש באלגוריתמים של למידת מכונה כדי לאמן ולבדוק מודלים באמצעות נתונים עצומים. ניתן לאחסן את הנתונים בפורמטים שונים אך כדי ליצור מודלים של שפה גדולה באמצעות LangChain, הסוג הנפוץ ביותר הוא JSON. נתוני ההדרכה והבדיקה צריכים להיות ברורים ומלאים ללא כל אי בהירות כדי שהמודל יוכל לבצע ביעילות.
מדריך זה ידגים את תהליך השימוש במנתח JSON pydantic ב-LangChain.
כיצד להשתמש ב-Pydantic (JSON) Parser ב-LangChain?
נתוני ה-JSON מכילים את הפורמט הטקסטואלי של נתונים שניתן לאסוף באמצעות גירוד אינטרנט ומקורות רבים אחרים כמו יומנים וכו'. כדי לאמת את דיוק הנתונים, LangChain משתמשת בספריית ה-pydantic מ-Python כדי לפשט את התהליך. כדי להשתמש במנתח JSON pydantic ב-LangChain, פשוט עברו על המדריך הזה:
שלב 1: התקן מודולים
כדי להתחיל בתהליך, פשוט התקן את מודול LangChain כדי להשתמש בספריות שלו לשימוש במנתח ב-LangChain:
צִפצוּף להתקין langchain
כעת, השתמש ב' התקנת pip ” הפקודה כדי לקבל את מסגרת OpenAI ולהשתמש במשאבים שלה:
צִפצוּף להתקין openai
לאחר התקנת המודולים, פשוט התחבר לסביבת OpenAI על ידי מתן מפתח ה-API שלו באמצעות ' אתה ' ו' getpass ' ספריות:
לייבא אותנוייבוא getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'מפתח API של OpenAI:' )

שלב 2: ייבוא ספריות
השתמש במודול LangChain כדי לייבא את הספריות הדרושות שניתן להשתמש בהן ליצירת תבנית עבור ההנחיה. התבנית להנחיה מתארת את השיטה לשאילת שאלות בשפה טבעית כדי שהמודל יוכל להבין את ההנחיה בצורה יעילה. כמו כן, ייבא ספריות כמו OpenAI ו-ChatOpenAI כדי ליצור רשתות באמצעות LLMs לבניית צ'אטבוט:
מ-langchain.prompts ייבוא (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
מאת langchain.llms ייבוא OpenAI
מאת langchain.chat_models ייבוא ChatOpenAI
לאחר מכן, ייבא ספריות pydantic כמו BaseModel, Field ו-validator כדי להשתמש במנתח JSON ב-LangChain:
מאת langchain.output_parsers ייבוא PydanticOutputParserמ-pydantic import BaseModel, Field, Validator
מהקלדת רשימת ייבוא
שלב 3: בניית מודל
לאחר קבלת כל הספריות לשימוש במנתח JSON pydantic, פשוט קבל את המודל הנבדק המעוצב מראש עם שיטת OpenAI():
model_name = 'text-davinci-003'טמפרטורה = 0.0
דגם = OpenAI ( שם המודל =שם_דגם, טֶמפֶּרָטוּרָה =טמפרטורה )
שלב 4: הגדר את ה-Actor BaseModel
בנו דגם נוסף כדי לקבל תשובות הקשורות לשחקנים כמו שמותיהם וסרטיהם על ידי בקשת הפילמוגרפיה של השחקן:
שחקן בכיתה ( דגם בסיס ) :name: str = שדה ( תיאור = 'שם השחקן הראשי' )
סרט_שמות: רשימה [ str ] = שדה ( תיאור = 'סרטים שבהם השחקן היה מוביל' )
actor_query = 'אני רוצה לראות את הפילמוגרפיה של כל שחקן'
מנתח = PydanticOutputParser ( pydantic_object =שחקן )
prompt = PromptTemplate (
תבנית = 'השב לבקשת המשתמש. \n {format_instructions} \n {שאילתא} \n ' ,
משתני_קלט = [ 'שאילתא' ] ,
משתנים_חלקיים = { 'פורמט_הוראות' : parser.get_format_instructions ( ) } ,
)
שלב 5: בדיקת מודל הבסיס
כל שעליך לעשות הוא לקבל את הפלט באמצעות הפונקציה parse() כאשר משתנה הפלט מכיל את התוצאות שנוצרו עבור ההנחיה:
_input = prompt.format_prompt ( שאילתא =actor_query )פלט = דגם ( _input.to_string ( ) )
parser.parse ( תְפוּקָה )
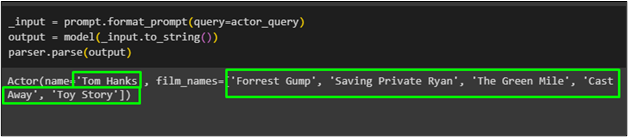
השחקן בשם ' טום הנקס ' עם רשימת הסרטים שלו הובא באמצעות הפונקציה הפידנטית מהמודל:
זה הכל על השימוש במנתח JSON pydantic ב-LangChain.
סיכום
כדי להשתמש במנתח JSON pydantic ב-LangChain, פשוט התקן את מודולי LangChain ו-OpenAI כדי להתחבר למשאבים ולספריות שלהם. לאחר מכן, ייבא ספריות כמו OpenAI ו-pydantic כדי לבנות מודל בסיס ולאמת את הנתונים בצורה של JSON. לאחר בניית מודל הבסיס, בצע את הפונקציה parse() והיא מחזירה את התשובות לפקודה. פוסט זה הדגים את תהליך השימוש במנתח JSON pydantic ב-LangChain.