כיצד פועלת צבירה קבוצתית ב- MongoDB?
יש להשתמש באופרטור $group כדי לקבץ את מסמכי הקלט לפי הביטוי _id שצוין. לאחר מכן הוא אמור להחזיר מסמך בודד עם סך כל הערכים עבור כל קבוצה נפרדת. כדי להתחיל עם היישום, יצרנו את אוסף 'ספרים' ב- MongoDB. לאחר יצירת אוסף 'ספרים', הכנסנו את המסמכים המשויכים לתחומים השונים. המסמכים מוכנסים לאוסף באמצעות שיטת insertMany() כאשר השאילתה שיש לבצע מוצגת להלן.
>db.Books.insertMany([{
_id:1,
כותרת: 'אנה קרנינה',
מחיר: 290,
שנה: 1879,
order_status: 'במלאי',
מחבר: {
'שם': 'ליאו טולסטוי'
}
},
{
_id:2,
כותרת: 'להרוג ציפור מלגלגת',
מחיר: 500,
שנה: 1960,
order_status: 'אזל במלאי',
מחבר: {
'שם': 'הרפר לי'
}
},
{
_id:3,
כותרת: 'אדם בלתי נראה',
מחיר: 312,
שנה: 1953,
order_status: 'במלאי',
מחבר: {
'שם': 'ראלף אליסון'
}
},
{
_id:4,
כותרת: 'אהובה',
מחיר: 370,
שנה: 1873,
order_status: 'out_of_stock',
מחבר: {
'שם': 'טוני מוריסון'
}
},
{
_id:5,
כותרת: 'דברים מתפרקים',
מחיר: 200,
שנה: 1958,
order_status: 'במלאי',
מחבר: {
'name': 'Chinua Achebe'
}
},
{
_id:6,
כותרת: 'הצבע הסגול',
מחיר: 510,
שנה: 1982,
order_status: 'אזל במלאי',
מחבר: {
'שם': 'אליס ווקר'
}
}
])
המסמכים מאוחסנים בהצלחה באוסף 'ספרים' מבלי להיתקל בשגיאה משום שהפלט מוכר כ'נכון'. כעת, אנו הולכים להשתמש במסמכים אלה של אוסף 'ספרים' לביצוע הצבירה של '$group'.

דוגמה מס' 1: שימוש ב-$group Aggregation
השימוש הפשוט בצבירה של $group מודגם כאן. השאילתה המצטברת הזינה תחילה את האופרטור '$group' ואז האופרטור '$group' לוקח את הביטויים כדי ליצור את המסמכים המקובצים.
>db.Books.aggregate([
{ $group:{ _id:'$author.name'} }
])
השאילתה שלמעלה של האופרטור $group מצוינת בשדה '_id' כדי לחשב את הערכים הכוללים עבור כל מסמכי הקלט. לאחר מכן, השדה '_id' מוקצה עם '$author.name' אשר יוצר קבוצה אחרת בשדה '_id'. הערכים הנפרדים של $author.name יוחזרו מכיוון שאיננו מחשבים ערכים מצטברים. לביצוע השאילתה המצטברת של $group יש את הפלט הבא. בשדה _id יש ערכים של author.names.

דוגמה מס' 2: שימוש ב-$group Aggregation עם $push Accumulator
הדוגמה של צבירה של $group אכן משתמשת בכל מצבר שכבר הוזכר לעיל. אבל אנחנו יכולים להשתמש בצברים בצבירה של $group. אופרטורי המצבר הם אלה המשמשים בשדות מסמכי קלט שאינם אלה ש'מקובצים' תחת '_id'. הבה נניח שאנו רוצים לדחוף את השדות של הביטוי למערך ואז מצבר '$push' נקרא באופרטור '$group'. הדוגמה תעזור לך להבין את מצבר ה-'$push' של ה-'$group' בצורה ברורה יותר.
>db.Books.aggregate([
{ $group : { _id : '$_id', year: { $push: '$year' } } }
]
).יפה();
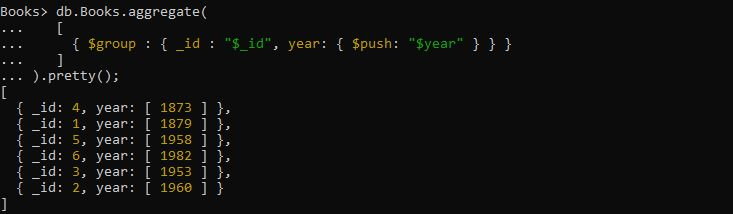
כאן, אנו רוצים לקבץ את תאריך שנת הפרסום של הספרים הנתונים במערך. יש ליישם את השאילתה לעיל כדי להשיג זאת. שאילתת הצבירה מסופקת עם הביטוי שבו האופרטור '$group' לוקח את ביטוי השדה '_id' ואת ביטוי השדה 'year' כדי לקבל את שנת הקבוצה באמצעות מצבר $push. הפלט שאוחזר מהשאילתה הספציפית הזו יוצר את מערך שדות השנה ומאחסן בתוכו את המסמך המקובץ המוחזר.
דוגמה מס' 3: שימוש ב-$group Aggregation עם מצבר '$min'.
לאחר מכן, יש לנו את מצבר '$min' המשמש בצבירה של $group כדי לקבל את ערך ההתאמה המינימלי מכל מסמך באוסף. ביטוי השאילתה עבור מצבר $min ניתן להלן.
>db.Books.aggregate([{
$group:{
_תְעוּדַת זֶהוּת:{
title: '$title',
order_status: '$order_status'
},
minPrice:{$min: '$price'}
}
}
])
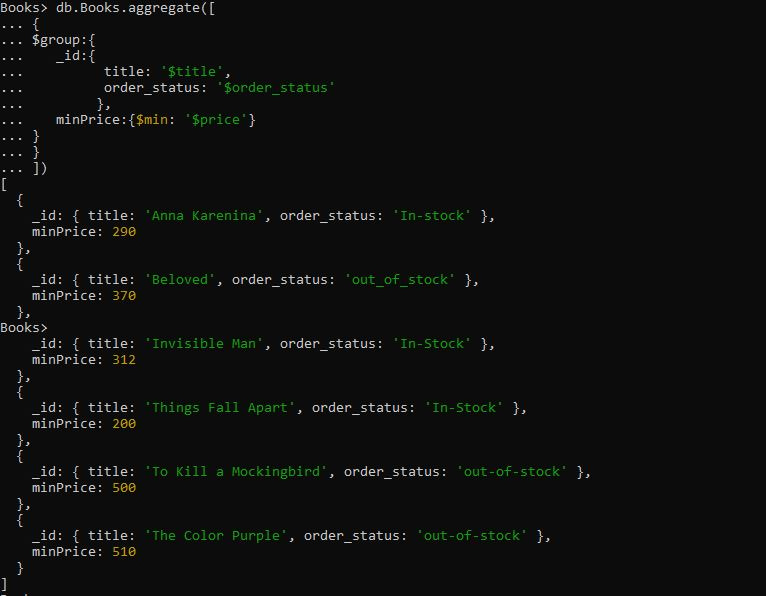
לשאילתה יש את ביטוי הצבירה '$group' שבו קיבצנו את המסמך עבור השדות 'כותרת' ו-'order_status'. לאחר מכן, סיפקנו את מצבר $min אשר קיבץ את המסמכים על ידי קבלת ערכי המחיר המינימליים מהשדות הלא מקובצים. כאשר אנו מריצים את השאילתה הזו של $min accumulator למטה, הוא מחזיר את המסמכים המקובצים לפי כותרת ו-order_status ברצף. מחיר המינימום מופיע ראשון, והמחיר הגבוה ביותר של המסמך ממוקם אחרון.
דוגמה מס' 4: השתמש ב-$group Aggregation עם $sum Accumulator
כדי לקבל את הסכום של כל השדות המספריים באמצעות האופרטור $group, נפרסת פעולת מצבר $sum. הערכים הלא מספריים באוספים נחשבים על ידי מצבר זה. בנוסף, אנו משתמשים כאן בצבירה של $match עם צבירה של $group. צבירת $match מקבלת את תנאי השאילתה הניתנים במסמך ומעבירה את המסמך המותאם לצבירה של $group אשר לאחר מכן מחזירה את סכום המסמך עבור כל קבוצה. עבור מצבר $sum, השאילתה מוצגת להלן.
>db.Books.aggregate([{ $match:{ order_status:'In-Stock'}},
{ $group:{ _id:'$author.name', totalBooks: { $sum:1 } }
}])
שאילתת הצבירה שלמעלה מתחילה באופרטור $match אשר מתאים לכל ה-'order_status' שהסטטוס שלהם הוא 'In-Stock' ומועבר ל-$group כקלט. לאחר מכן, לאופרטור $group יש את הביטוי $sum accumulator שמוציא את הסכום של כל הספרים במניה. שימו לב שה-'$sum:1' מוסיף 1 לכל מסמך ששייך לאותה קבוצה. הפלט כאן הראה רק שני מסמכים מקובצים עם ה-'order_status' המשויך ל-'In-Stock'.

דוגמה מס' 5: השתמש ב-$group Aggregation עם $sort Aggregation
האופרטור $group כאן משמש עם האופרטור '$sort' המשמש למיון המסמכים המקובצים. לשאילתה הבאה יש שלושה שלבים לפעולת המיון. ראשית הוא שלב $ההתאמה, לאחר מכן שלב $group, והאחרון הוא שלב $sort הממיין את המסמך המקובץ.
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ authorName :'$author.name'}, totalBooks: { $sum:1} } },
{ $sort:{ authorName:1}}
])
הנה, הבאנו את המסמך המותאם ש-'order_status' שלו אזל מהמלאי. לאחר מכן, המסמך המותאם מוזן בשלב $group אשר קיבץ את המסמך עם השדה 'authorName' ו-'totalBooks'. הביטוי $group משויך לצובר $sum למספר הכולל של ספרים 'אזל במלאי'. לאחר מכן ממוינים המסמכים המקובצים עם הביטוי $sort בסדר עולה שכן '1' כאן מציין את הסדר העולה. מסמך הקבוצה הממוין בסדר שצוין מתקבל בפלט הבא.

דוגמה מס' 6: השתמש ב-$group Aggregation for Distinct Value
הליך הצבירה גם מקבץ את המסמכים לפי פריט באמצעות האופרטור $group כדי לחלץ את ערכי הפריט הנבדלים. תן לנו את ביטוי השאילתה של הצהרה זו ב- MongoDB.
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();שאילתת הצבירה מוחלת על אוסף הספרים כדי לקבל את הערך המובחן של מסמך הקבוצה. ה-$group כאן לוקח את הביטוי _id שמוציא את הערכים המובחנים כפי שהזנו לו את השדה 'כותרת'. הפלט של מסמך הקבוצה מתקבל עם הפעלת שאילתה זו שיש לה את קבוצת שמות הכותרות מול השדה _id.

סיכום
המדריך נועד לנקות את הרעיון של אופרטור הצבירה $group לקיבוץ המסמך במסד הנתונים של MongoDB. הגישה המצטברת של MongoDB משפרת את תופעות הקיבוץ. מבנה התחביר של האופרטור $group מודגם בתוכניות לדוגמה. בנוסף לדוגמא הבסיסית של האופרטורים $group, השתמשנו באופרטור זה גם עם כמה מצברים כמו $push, $min, $sum ואופרטורים כמו $match ו-$sort.