LangChain היא המסגרת שניתן להשתמש בה כדי לייבא ספריות ותלות לבניית מודלים של שפה גדולה או LLMs. דגמי השפה משתמשים בזיכרון כדי לאחסן נתונים או היסטוריה במסד הנתונים כתצפית כדי לקבל את ההקשר של השיחה. הזיכרון מוגדר לאחסן את ההודעות העדכניות ביותר כך שהמודל יוכל להבין את ההנחיות המעורפלות שניתן על ידי המשתמש.
בלוג זה מסביר את תהליך השימוש בזיכרון ב-LLMChain דרך LangChain.
כיצד להשתמש בזיכרון ב-LLMChain דרך LangChain?
כדי להוסיף זיכרון ולהשתמש בו ב-LLMChain דרך LangChain, ניתן להשתמש בספריית ConversationBufferMemory על ידי ייבוא מה-LangChain.
כדי ללמוד את תהליך השימוש בזיכרון ב-LLMChain דרך LangChain, עברו על המדריך הבא:
שלב 1: התקן מודולים
ראשית, התחל את תהליך השימוש בזיכרון על ידי התקנת ה-LangChain באמצעות הפקודה pip:
pip להתקין langchain
התקן את מודולי OpenAI כדי לקבל את התלות או הספריות שלו לבניית LLMs או מודלים של צ'אט:
pip להתקין openai
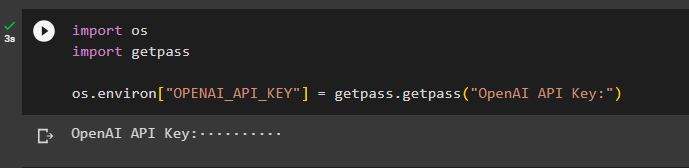
הגדר את הסביבה עבור OpenAI באמצעות מפתח ה-API שלו על ידי ייבוא ספריות מערכת ההפעלה ו-getpass:
לייבא אותנוייבוא getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
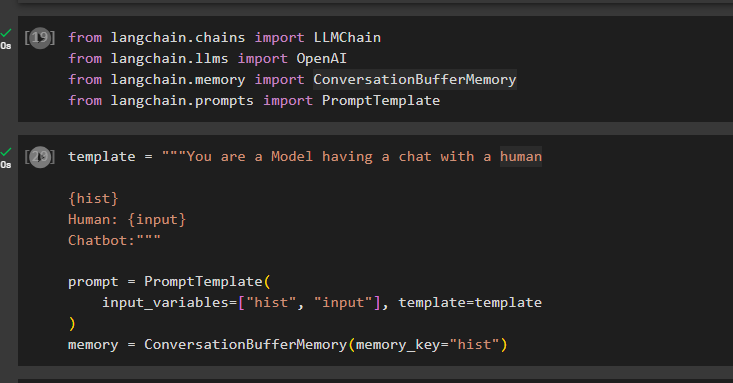
שלב 2: ייבוא ספריות
לאחר הגדרת הסביבה, פשוט ייבא את הספריות כמו ConversationBufferMemory מה-LangChain:
מאת langchain.chains ייבוא LLMChainמאת langchain.llms ייבוא OpenAI
מ-langchain.memory ייבוא ConversationBufferMemory
מ-langchain.prompts ייבוא PromptTemplate
הגדר את התבנית עבור ההנחיה באמצעות משתנים כמו 'קלט' כדי לקבל את השאילתה מהמשתמש ו'היסט' לאחסון הנתונים בזיכרון המאגר:
template = '''אתה דוגמנית שמנהלת צ'אט עם אדם{היסט}
אנושי: {קלט}
צ'אטבוט:'''
prompt = PromptTemplate(
input_variables=['היסט', 'קלט'], תבנית=תבנית
)
memory = ConversationBufferMemory(memory_key='hist')
שלב 3: הגדרת LLM
לאחר בניית התבנית עבור השאילתה, הגדר את שיטת LLMChain() באמצעות מספר פרמטרים:
llm = OpenAI()llm_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=נכון,
זיכרון=זיכרון,
)
שלב 4: בדיקת LLMChain
לאחר מכן, בדוק את LLMChain באמצעות משתנה הקלט כדי לקבל את ההנחיה מהמשתמש בצורה טקסטואלית:
llm_chain.predict(input='שלום לך חבר שלי') 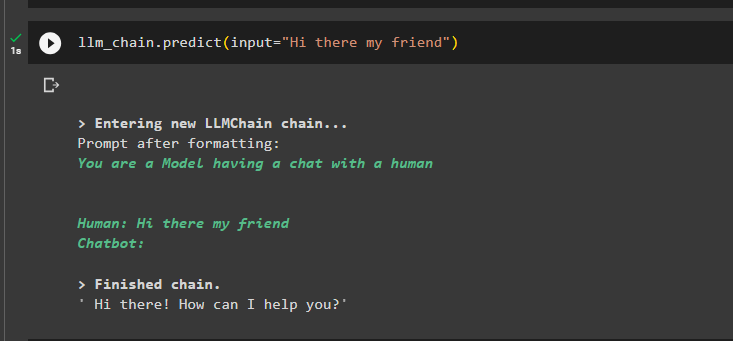
השתמש בקלט אחר כדי לקבל את הנתונים המאוחסנים בזיכרון לחילוץ פלט באמצעות ההקשר:
llm_chain.predict(input='טוב! אני טוב - מה שלומך') 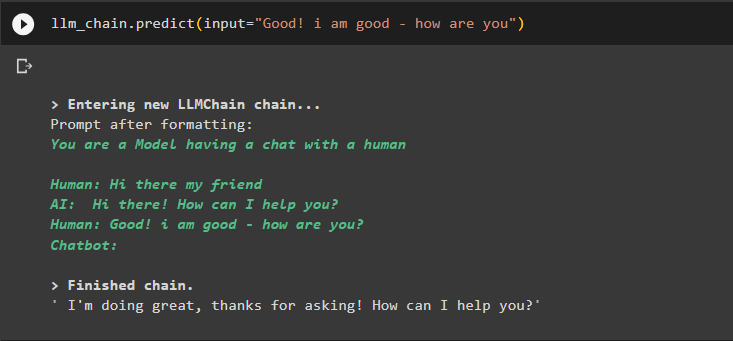
שלב 5: הוספת זיכרון למודל צ'אט
ניתן להוסיף את הזיכרון ל-LLMChain מבוסס מודל הצ'אט על ידי ייבוא הספריות:
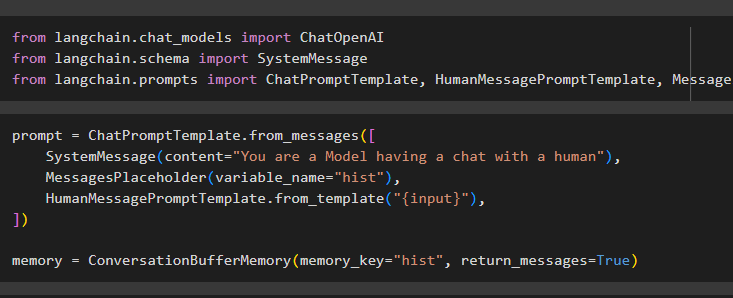
מאת langchain.chat_models ייבוא ChatOpenAIמ-langchain.schema ייבוא SystemMessage
מאת langchain.prompts ייבוא ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
הגדר את תבנית ההנחיה באמצעות ה-ConversationBufferMemory() באמצעות משתנים שונים כדי להגדיר את הקלט מהמשתמש:
prompt = ChatPromptTemplate.from_messages([SystemMessage(content='אתה דוגמנית שמנהלת צ'אט עם אדם'),
MessagesPlaceholder(variable_),
HumanMessagePromptTemplate.from_template('{input}'),
])
memory = ConversationBufferMemory(memory_key='hist', return_messages=True)
שלב 6: הגדרת LLMChain
הגדר את שיטת LLMChain() כדי להגדיר את המודל באמצעות ארגומנטים ופרמטרים שונים:
llm = ChatOpenAI()chat_llm_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=נכון,
זיכרון=זיכרון,
)
שלב 7: בדיקת LLMChain
בסוף, פשוט בדוק את ה-LLMChain באמצעות הקלט כדי שהמודל יוכל ליצור את הטקסט לפי ההנחיה:
chat_llm_chain.predict(input='שלום לך חבר שלי') 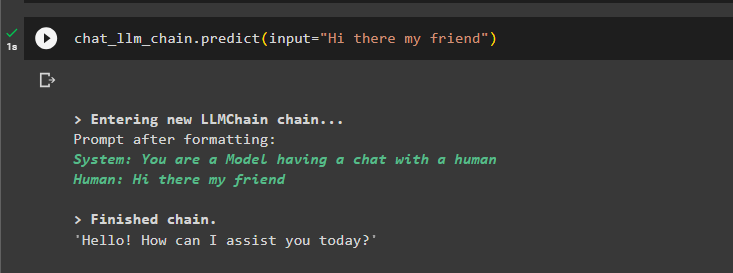
המודל אחסן את השיחה הקודמת בזיכרון ומציג אותה לפני הפלט בפועל של השאילתה:
llm_chain.predict(input='טוב! אני טוב - מה שלומך') 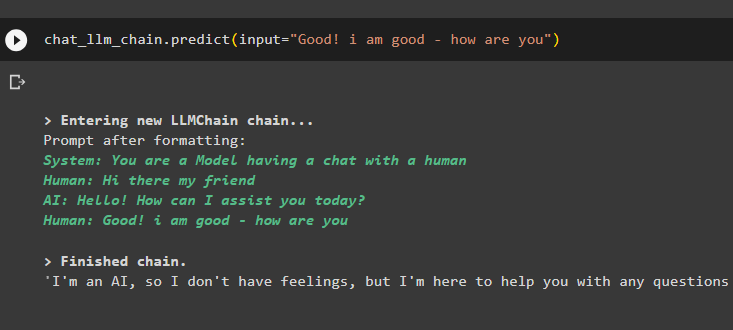
זה הכל על שימוש בזיכרון ב-LLMChain באמצעות LangChain.
סיכום
כדי להשתמש בזיכרון ב-LLMChain דרך מסגרת LangChain, פשוט התקן את המודולים כדי להגדיר את הסביבה כדי לקבל את התלות מהמודולים. לאחר מכן, פשוט ייבא את הספריות מ-LangChain כדי להשתמש בזיכרון המאגר לאחסון השיחה הקודמת. המשתמש יכול גם להוסיף זיכרון למודל הצ'אט על ידי בניית ה-LLMChain ולאחר מכן בדיקת השרשרת על ידי מתן הקלט. מדריך זה הרחיב את תהליך השימוש בזיכרון ב-LLMChain דרך LangChain.