מדריך זה ימחיש כיצד להשתמש ב- VectorStoreRetrieverMemory באמצעות מסגרת LangChain.
כיצד להשתמש ב-VectorStoreRetrieverMemory ב-LangChain?
VectorStoreRetrieverMemory היא הספרייה של LangChain שניתן להשתמש בה כדי לחלץ מידע/נתונים מהזיכרון באמצעות מאגרי הווקטור. ניתן להשתמש בחנויות וקטוריות כדי לאחסן ולנהל נתונים כדי לחלץ את המידע ביעילות בהתאם להנחיה או לשאילתה.
כדי ללמוד את תהליך השימוש ב-VectorStoreRetrieverMemory ב-LangChain, פשוט עברו על המדריך הבא:
שלב 1: התקן מודולים
התחל את תהליך השימוש בשחזור הזיכרון על ידי התקנת ה-LangChain באמצעות הפקודה pip:
pip להתקין langchain
התקן את מודולי FAISS כדי לקבל את הנתונים באמצעות חיפוש הדמיון הסמנטי:
pip להתקין faiss-gpu 
התקן את מודול chromadb לשימוש במסד הנתונים Chroma. זה עובד כמאגר הווקטור לבניית הזיכרון עבור הרטריבר:
pip להתקין chromadb 
יש צורך להתקין מודול tiktoken נוסף שניתן להשתמש בו כדי ליצור אסימונים על ידי המרת נתונים לנתחים קטנים יותר:
pip להתקין tiktoken 
התקן את מודול OpenAI כדי להשתמש בספריות שלו לבניית LLMs או צ'אטבוטים באמצעות הסביבה שלו:
pip להתקין openai 
הגדר את הסביבה ב-Python IDE או במחברת באמצעות מפתח ה-API מחשבון OpenAI:
יְבוּא אתהיְבוּא getpass
אתה . בְּעֵרֶך [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'מפתח API של OpenAI:' )
שלב 2: ייבוא ספריות
השלב הבא הוא לקבל את הספריות מהמודולים האלה לשימוש בשחזור הזיכרון ב-LangChain:
מ langchain. הנחיות יְבוּא PromptTemplateמ תאריך שעה יְבוּא תאריך שעה
מ langchain. llms יְבוּא OpenAI
מ langchain. הטבעות . openai יְבוּא OpenAIEbeddings
מ langchain. שרשראות יְבוּא ConversationChain
מ langchain. זיכרון יְבוּא VectorStoreRetrieverMemory
שלב 3: אתחול חנות וקטור
מדריך זה משתמש במסד הנתונים Chroma לאחר ייבוא ספריית FAISS כדי לחלץ את הנתונים באמצעות פקודת הקלט:
יְבוּא פאיסמ langchain. דוקטורט יְבוּא InMemoryDocstore
#ייבוא ספריות להגדרת מסדי הנתונים או מאגרי וקטור
מ langchain. חנויות וקטורים יְבוּא FAISS
#צור הטמעות וטקסטים כדי לאחסן אותם בחנויות הוקטורים
embedding_size = 1536
אינדקס = פאיס. IndexFlatL2 ( embedding_size )
embedding_fn = OpenAIEbeddings ( ) . embed_query
vectorstore = FAISS ( embedding_fn , אינדקס , InMemoryDocstore ( { } ) , { } )
שלב 4: בניית רטריבר מגובה בחנות וקטור
בנה את הזיכרון כדי לאחסן את ההודעות האחרונות בשיחה ולקבל את ההקשר של הצ'אט:
מחזיר = vectorstore. as_retriever ( search_kwargs = כתיב ( ק = 1 ) )זיכרון = VectorStoreRetrieverMemory ( מחזיר = מחזיר )
זיכרון. save_context ( { 'קֶלֶט' : 'אני אוהב לאכול פיצה' } , { 'תְפוּקָה' : 'פַנטַסטִי' } )
זיכרון. save_context ( { 'קֶלֶט' : 'אני טוב בכדורגל' } , { 'תְפוּקָה' : 'בסדר' } )
זיכרון. save_context ( { 'קֶלֶט' : 'אני לא אוהב את הפוליטיקה' } , { 'תְפוּקָה' : 'בטוח' } )
בדוק את הזיכרון של הדגם באמצעות הקלט שסופק על ידי המשתמש עם ההיסטוריה שלו:
הדפס ( זיכרון. load_memory_variables ( { 'מיידי' : 'איזה ספורט עלי לראות?' } ) [ 'הִיסטוֹרִיָה' ] ) 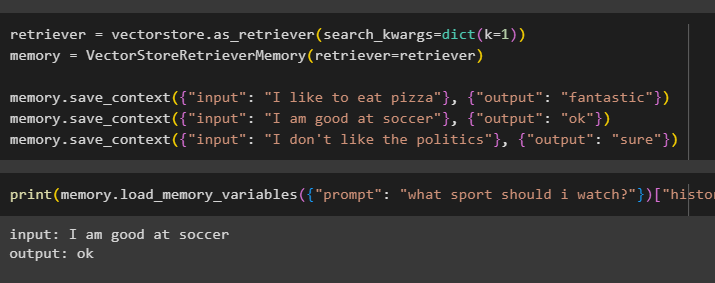
שלב 5: שימוש ברטריבר בשרשרת
השלב הבא הוא השימוש בשחזור זיכרון עם השרשראות על ידי בניית ה-LLM בשיטת OpenAI() והגדרת תבנית ההנחיה:
llm = OpenAI ( טֶמפֶּרָטוּרָה = 0 )_DEFAULT_TEMPLATE = ''' זוהי אינטראקציה בין אדם למכונה
המערכת מייצרת מידע שימושי עם פרטים תוך שימוש בהקשר
אם למערכת אין את התשובה בשבילך, היא פשוט אומרת שאין לי את התשובה
מידע חשוב משיחה:
{הִיסטוֹרִיָה}
(אם הטקסט לא רלוונטי אל תשתמש בו)
צ'אט נוכחי:
אנושי: {קלט}
AI:'''
מיידי = PromptTemplate (
משתני_קלט = [ 'הִיסטוֹרִיָה' , 'קֶלֶט' ] , תבנית = _DEFAULT_TEMPLATE
)
#configure את ה-ConversationChain() באמצעות הערכים עבור הפרמטרים שלו
שיחה_עם_סיכום = ConversationChain (
llm = llm ,
מיידי = מיידי ,
זיכרון = זיכרון ,
מִלוּלִי = נָכוֹן
)
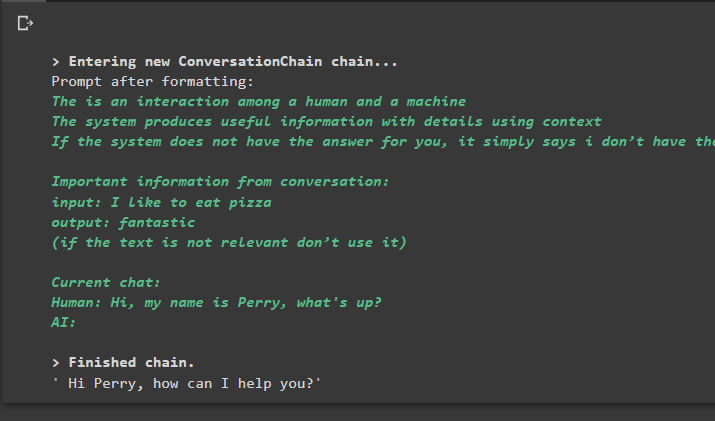
שיחה_עם_סיכום. לנבא ( קֶלֶט = 'היי, קוראים לי פרי, מה קורה?' )
תְפוּקָה
ביצוע הפקודה מפעיל את השרשרת ומציג את התשובה שסופק על ידי המודל או ה-LLM:
המשך בשיחה באמצעות הנחיה המבוססת על הנתונים המאוחסנים במאגר הוקטורים:
שיחה_עם_סיכום. לנבא ( קֶלֶט = 'מהו הספורט האהוב עליי?' ) 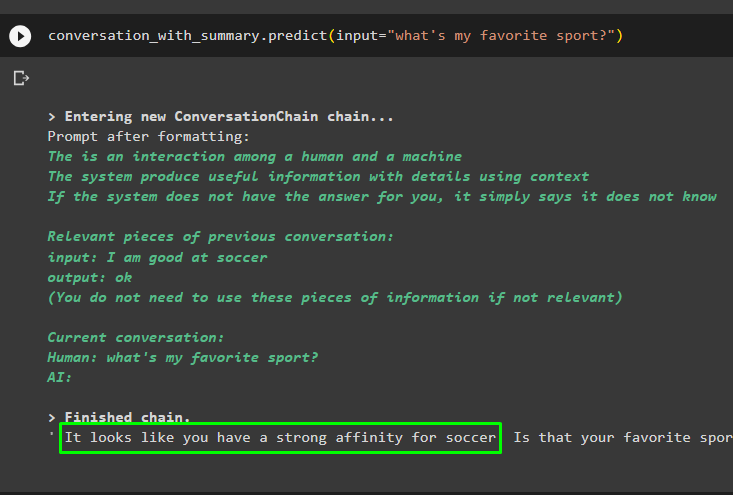
ההודעות הקודמות מאוחסנות בזיכרון של המודל אשר יכול לשמש את המודל כדי להבין את ההקשר של ההודעה:
שיחה_עם_סיכום. לנבא ( קֶלֶט = 'מה האוכל האהוב עליי' ) 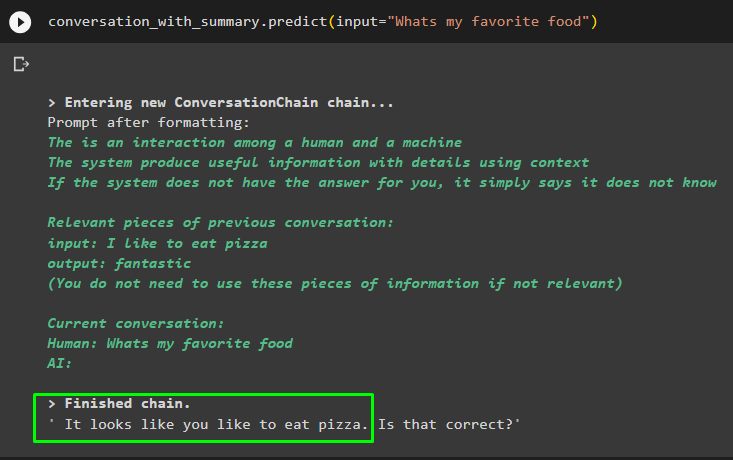
קבל את התשובה שסופקה לדגם באחת מההודעות הקודמות כדי לבדוק איך שחזור הזיכרון עובד עם מודל הצ'אט:
שיחה_עם_סיכום. לנבא ( קֶלֶט = 'מה השם שלי?' )המודל הציג נכון את הפלט באמצעות חיפוש הדמיון מהנתונים המאוחסנים בזיכרון:
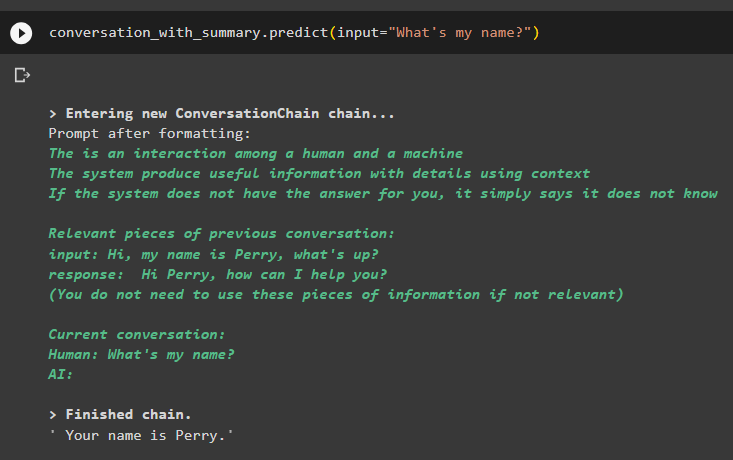
זה הכל על השימוש ב-Vector Store Retriever ב-LangChain.
סיכום
כדי להשתמש ברטריבר הזיכרון המבוסס על חנות וקטורית ב-LangChain, פשוט התקן את המודולים והמסגרות והגדר את הסביבה. לאחר מכן, ייבא את הספריות מהמודולים כדי לבנות את מסד הנתונים באמצעות Chroma ולאחר מכן הגדר את תבנית ההנחיה. בדוק את הרטריבר לאחר שמירת נתונים בזיכרון על ידי הפעלת השיחה ושאילת שאלות הקשורות להודעות הקודמות. מדריך זה הרחיב את תהליך השימוש בספריית VectorStoreRetrieverMemory ב-LangChain.