6.1 מבוא
מחשבים מודרניים לשימוש כללי הם משני סוגים: CISC ו-RISC. CISC ראשי תיבות של Complex Instruction Set Computer. RISK ראשי תיבות של Reduced Instruction Set Computer. המיקרו-מעבדים 6502 או 6510, כפי שישים למחשב Commodore-64, דומים יותר לארכיטקטורת RISC מאשר לארכיטקטורת CISC.
למחשבי RISC יש בדרך כלל הוראות שפת הרכבה קצרות יותר (לפי מספר בתים) בהשוואה למחשבי CISC.
הערה : בין אם מדובר במחשב CISC, RISC או ישן, ציוד היקפי מתחיל מיציאה פנימית ועובר החוצה דרך יציאה חיצונית על המשטח האנכי של יחידת המערכת של המחשב (יחידת הבסיס) ואל ההתקן החיצוני.
ניתן לראות הוראה טיפוסית של מחשב CISC כמו חיבור של מספר הוראות שפת assembly קצרות להוראת שפת assembly אחת ארוכה יותר, מה שהופך את ההוראה המתקבלת למורכבת. בפרט, מחשב CISC טוען את האופרנדים מהזיכרון לתוך אוגרי המיקרו-מעבד, מבצע פעולה, ואז מאחסן את התוצאה בחזרה בזיכרון, הכל בהוראה אחת. מצד שני, מדובר בשלוש הוראות לפחות (קיצור) למחשב RISC.
ישנן שתי סדרות פופולריות של מחשבי CISC: מחשבי המיקרו-מעבד של אינטל ומחשבי המיקרו-מעבדים של AMD. AMD ראשי תיבות של Advanced Micro Devices; זוהי חברה לייצור מוליכים למחצה. סדרות המיקרו-מעבדים של אינטל, לפי סדר הפיתוח, הן 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron ו-Xeon. הוראות שפת ההרכבה עבור מעבדי אינטל המוקדמים כגון 8086 ו-8088 אינן מורכבות במיוחד. עם זאת, הם מורכבים עבור המיקרו-מעבדים החדשים. המיקרו-מעבדים האחרונים של AMD לסדרת CISC הם Ryzen, Opteron, Athlon, Turion, Phenom ו-Sempron. המיקרו-מעבדים של אינטל ו-AMD ידועים כמעבדי x86.
ARM ראשי תיבות של Advanced RISC Machine. ארכיטקטורות ARM מגדירות משפחה של מעבדי RISC המתאימים לשימוש במגוון רחב של יישומים. בעוד שמעבדים רבים של אינטל ו-AMD נמצאים בשימוש במחשבים אישיים שולחניים, מעבדי ARM רבים משמשים כמעבדים משובצים במערכות קריטיות לבטיחות כגון בלמים נגד נעילה לרכב וכמעבדים לשימוש כללי בשעונים חכמים, טלפונים ניידים, טאבלטים ומחשבים ניידים . למרות שניתן לראות את שני סוגי המיקרו-מעבדים במכשירים קטנים וגדולים, מעבדי RISC נמצאים יותר במכשירים קטנים מאשר במכשירים גדולים.
Word מחשב
אם אומרים על מחשב שהוא מחשב של מילה של 32 סיביות, זה אומר שהמידע מאוחסן, מועבר ומתופעל בצורה של קודים בינאריים של שלושים ושתיים סיביות בחלק הפנימי של לוח האם. זה גם אומר שהרגיסטרים לשימוש כללי במיקרו-מעבד של המחשב הם ברוחב של 32 סיביות. האוגרים A, X ו-Y של המיקרו-מעבד 6502 הם אוגרים למטרות כלליות. הם ברוחב של שמונה סיביות, ולכן מחשב Commodore-64 הוא מחשב מילים של שמונה סיביות.
קצת אוצר מילים
X86 מחשבים
המשמעויות של byte, word, doubleword, quadword ו-double-quadword הן כדלקמן עבור מחשבי x86:
- בייט : 8 ביטים
- מִלָה : 16 ביטים
- Doubleword : 32 ביטים
- Quadword : 64 סיביות
- כפול מרובע מילים : 128 סיביות
מחשבי ARM
המשמעויות של בתים, חצי מילה, מילה ומילה כפולה הן כדלקמן עבור מחשבי ARM:
- בייט : 8 ביטים
- להיות חצי : 16 ביטים
- מִלָה : 32 ביטים
- Doubleword : 64 סיביות
יש לציין את ההבדלים והדמיון עבור השמות (והערכים) x86 ו-ARM.
הערה : מספרי הסימנים השלמים בשני סוגי המחשבים הם משלים של שניים.
מיקום זיכרון
עם מחשב Commodore-64, מיקום זיכרון הוא בדרך כלל בת אחד, אך יכול להיות שני בתים עוקבים מדי פעם כאשר לוקחים בחשבון את המצביעים (פנייה עקיפה). במחשב x86 מודרני, מיקום הזיכרון הוא 16 בתים רצופים כאשר עוסקים ב-Quadword כפול של 16 בתים (128 סיביות), 8 בתים רצופים כאשר עוסקים ב-quadword של 8 בתים (64 סיביות), 4 בתים רצופים כאשר עוסקים ב-Doubleword של 4 בתים (32 סיביות), 2 בתים עוקבים כאשר עוסקים במילה של 2 בתים (16 סיביות), ו-1 בייט כאשר עוסקים בבייט (8 סיביות). במחשב ARM מודרני, מיקום הזיכרון הוא 8 בתים רצופים כאשר עוסקים במילה כפולה של 8 בתים (64 סיביות), 4 בתים רצופים כאשר עוסקים במילה של 4 בתים (32 סיביות), 2 בתים רצופים כאשר עוסקים בחצי מילה של 2 בתים (16 סיביות), ו-1 בייט כאשר עוסקים בבייט (8 סיביות).
פרק זה מסביר מה נפוץ בארכיטקטורות CISC ו-RISC ומה ההבדלים ביניהם. זה נעשה בהשוואה ל-6502 µP ולמחשב commodore-64 היכן שהוא ישים.
6.2 תרשים בלוקים של לוח האם של מחשב מודרני
PC ראשי תיבות של Personal Computer. להלן תרשים בלוקים בסיסי גנרי עבור לוח אם מודרני עם מעבד מיקרו יחיד למחשב אישי. זה מייצג לוח אם CISC או RISC.
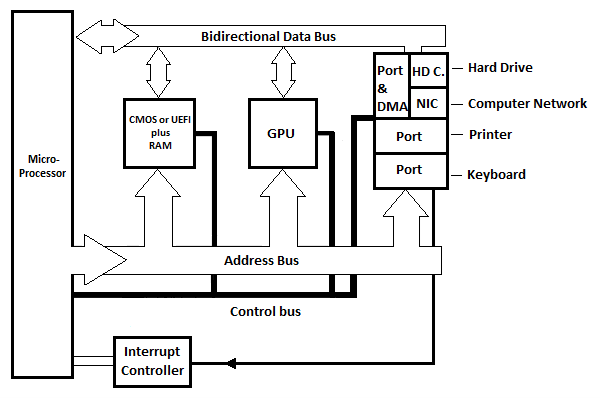
איור 6.21 תרשים בלוקים בסיסי של לוח האם של מחשב מודרני
שלוש יציאות פנימיות מוצגות בתרשים, אך ישנן יותר בפועל. לכל יציאה יש אוגר שניתן לראות בו כפורט עצמו. לכל מעגל יציאה יש לפחות אוגר נוסף שניתן לכנותו 'אוגר סטטוס'. מאגר המצב מציין את היציאה לתוכנית ששולחת את אות ההפסקה למיקרו-מעבד. קיים מעגל בקר פסיקה (לא מוצג) המבדיל בין קווי הפסיקה השונים מהיציאות השונות ויש לו רק כמה קווים ל-µP.
HD.C בתרשים מייצג כרטיס כונן קשיח. NIC ראשי תיבות של Network Interface Card. כרטיס הכונן הקשיח (מעגל) מחובר לכונן הקשיח שנמצא בתוך יחידת הבסיס (יחידת המערכת) של המחשב המודרני. כרטיס ממשק הרשת (מעגל) מחובר באמצעות כבל חיצוני למחשב אחר. בתרשים, יש יציאה אחת ו-DMA (עיין באיור הבא) המחוברים לכרטיס הדיסק הקשיח ו/או לכרטיס ממשק הרשת. DMA קיצור של Direct Memory Access.
זכור מפרק המחשב Commodore-64 שכדי לשלוח את הבייטים מהזיכרון לכונן הדיסקים או למחשב אחר, יש להעתיק כל בייט לרישום במיקרו-מעבד לפני העתקתו ליציאה הפנימית המתאימה, ולאחר מכן אוטומטית. למכשיר. על מנת לקבל את הבתים מכונן הדיסקים או מחשב אחר לזיכרון, יש להעתיק כל בייט מאוגר היציאות הפנימי המתאים לאוגר מיקרו-מעבד לפני העתקתו לזיכרון. זה בדרך כלל לוקח זמן רב אם מספר הבתים בזרם גדול. הפתרון להעברה מהירה הוא שימוש ב- Direct Memory Access (מעגל) ללא מעבר דרך המיקרו-מעבד.
מעגל ה-DMA נמצא בין היציאה ל-HD. C או NIC. עם הגישה הישירה לזיכרון של מעגל ה-DMA, ההעברה של זרמים גדולים של בתים היא ישירות בין מעגל ה-DMA לזיכרון (RAM) ללא המשך השתתפותו של המיקרו-מעבד. ה-DMA משתמש באפיק הכתובות ובאוטובוס הנתונים במקום µP. משך ההעברה הכולל קצר יותר מאשר אם יש להשתמש ב- µP hard. גם HD C. וגם NIC משתמשים ב-DMA כאשר יש להם זרם גדול של נתונים (בתים) להעברה עם RAM (הזיכרון).
GPU ראשי תיבות של Graphics Processing Unit. הבלוק הזה בלוח האם אחראי על שליחת הטקסט והתמונות הנעות או הסטילס למסך.
עם המחשבים המודרניים (מחשבים אישיים), אין זיכרון לקריאה בלבד (ROM). עם זאת, יש את ה-BIOS או UEFI שהוא סוג של זיכרון RAM לא נדיף. המידע ב-BIOS נשמר למעשה על ידי סוללה. הסוללה היא זו ששומרת למעשה גם על טיימר השעון, בזמן ובתאריך המתאים למחשב. UEFI הומצא לאחר ה-BIOS, והחליף את ה-BIOS למרות שה-BIOS עדיין רלוונטי למדי במחשבים מודרניים. נדון יותר על אלה מאוחר יותר!
במחשבי PC מודרניים, אפיקי הכתובת והנתונים בין µP למעגלי היציאה הפנימיים (והזיכרון) אינם אפיקים מקבילים. הם אפיקים טוריים שצריכים שני מוליכים לשידור בכיוון אחד ועוד שני מוליכים לשידור בכיוון ההפוך. משמעות הדבר היא, למשל, שניתן לשלוח 32 סיביות בסדרה (ביט אחד אחרי השני) לכל כיוון.
אם השידור הטורי הוא רק בכיוון אחד עם שני מוליכים (שני קווים), זה אמור להיות חצי דופלקס. אם השידור הטורי הוא בשני הכיוונים עם ארבעה מוליכים, זוג אחד לכל כיוון, שנאמר שהוא דופלקס מלא.
כל הזיכרון של המחשב המודרני עדיין מורכב מסדרה של מיקומי בתים: שמונה ביטים לבייט. למחשב מודרני יש שטח זיכרון של לפחות 4 גיגה בייט = 4 x 210 x 2 10 x 2 10 = 4 x 1,073,741,824 10 בתים = 4 x 1024 10/sub> x 1024 10 x 1024 10 = 4 x 1,073,741,824 10 .
הערה : למרות שלא מוצג מעגל טיימר בלוח האם הקודם, לכל לוחות האם המודרניים יש מעגלי טיימר.
6.3 יסודות ארכיטקטורת המחשב x64
6.31 סט הרישום של x64
המיקרו-מעבד של 64 סיביות של סדרת המיקרו-מעבדים x86 הוא מיקרו-מעבד של 64 סיביות. זה די מודרני להחליף את מעבד 32 סיביות מאותה סדרה. הרישומים הכלליים של המיקרו-מעבד ה-64-bit ושמותיהם הם כדלקמן:
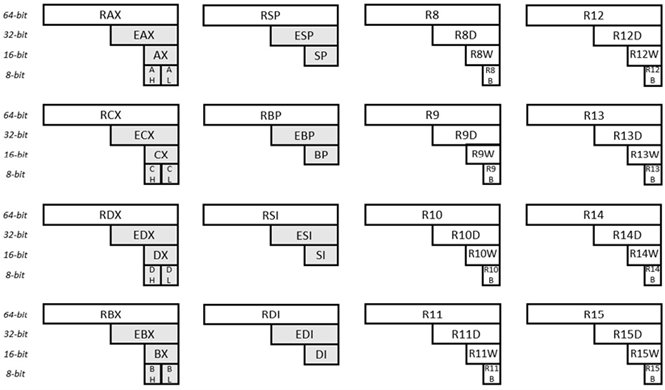
איור 6.31 רישומי מטרה כללית עבור x64
שישה עשר (16) אוגרים לשימוש כללי מוצגים באיור הנתון. כל אחד מהאוגרים הללו הוא ברוחב של 64 סיביות. בהסתכלות על האוגר בפינה השמאלית העליונה, 64 הסיביות מזוהות כ-RAX. 32 הסיביות הראשונות של אותו אוגר זה (מימין) מזוהות כ-EAX. 16 הסיביות הראשונות של אותו אוגר זה (מימין) מזוהות כ-AX. הבית השני (מימין) של אותו אוגר מזוהה כ-AH (H כאן פירושו גבוה). והבית הראשון (של אותו אוגר זה) מזוהה כ-AL (L כאן אומר נמוך). בהסתכלות על האוגר בפינה השמאלית התחתונה, 64 הסיביות מזוהות כ-R15. 32 הסיביות הראשונות של אותו אוגר זה מזוהות כ-R15D. 16 הסיביות הראשונות של אותו אוגר זה מזוהות כ-R15W. והבייט הראשון מזוהה כ-R15B. שמות הרשמים האחרים (ותתי האוגרים) מוסברים באופן דומה.
ישנם כמה הבדלים בין Intel ו-AMD µPs. המידע בסעיף זה מיועד לאינטל.
עם ה-6502 µP, אוגר ה-Programmer Counter (לא נגיש ישירות) שמכיל את ההוראה הבאה שתתבצע הוא ברוחב של 16 סיביות. כאן (x64), מונה התוכנית נקרא מצביע ההוראות, והוא ברוחב 64 סיביות. זה מסומן כ-RIP. המשמעות היא שה-x64 µP יכול לתת מענה לעד 264 = 1.844674407 x 1019 (למעשה 18,446,744,073,709,551,616) מיקומי בתים בזיכרון. RIP אינו פנקס למטרות כלליות.
ה-Stack Pointer Register או RSP הוא בין 16 האוגרים לשימוש כללי. זה מצביע על כניסת המחסנית האחרונה בזיכרון. כמו עם 6502 µP, הערימה של x64 גדלה כלפי מטה. עם ה-x64, הערימה ב-RAM משמשת לאחסון כתובות ההחזרה עבור תתי שגרות. הוא משמש גם לאחסון 'מרחב הצללים' (עיין בדיון הבא).
ל-6502 µP יש אוגר מצב מעבד של 8 סיביות. המקבילה ב-x64 נקראת אוגר RFLAGS. אוגר זה מאחסן את הדגלים המשמשים לתוצאות הפעולות ולשליטה במעבד (µP). הוא ברוחב של 64 סיביות. 32 הסיביות הגבוהות יותר שמורות ואינן בשימוש כרגע. הטבלה הבאה נותנת את השמות, האינדקס והמשמעויות עבור הביטים הנפוצים באוגר RFLAGS:
| טבלה 6.31.1 דגלי RFLAGS (ביטים) הנפוצים ביותר |
|||
|---|---|---|---|
| סֵמֶל | קצת | שֵׁם | מַטָרָה |
| CF | 0 | לשאת | זה מוגדר אם פעולה אריתמטית מייצרת העברה או הלוואה מהחלק המשמעותי ביותר של התוצאה; ניקה אחרת. דגל זה מציין תנאי גלישה עבור אריתמטיקה של מספר שלם ללא סימן. הוא משמש גם באריתמטיקה בעלת דיוק רב. |
| PF | 2 | שִׁוּוּי | זה מוגדר אם הבית הכי פחות משמעותי של התוצאה מכיל מספר זוגי של 1 סיביות; ניקה אחרת. |
| שֶׁל | 4 | לְהַתְאִים | זה מוגדר אם פעולת אריתמטית מייצרת העברה או שאילה מתוך סיביות 3 של התוצאה; ניקה אחרת. דגל זה משמש בחשבון עשרוני מקודד בינארי (BCD). |
| ZF | 6 | אֶפֶס | זה מוגדר אם התוצאה היא אפס; ניקה אחרת. |
| SF | 7 | סִימָן | הוא מוגדר אם הוא שווה לסיבית הכי משמעותית של התוצאה שהיא סיבית הסימן של מספר שלם עם סימן (0 מציין ערך חיובי ו-1 מציין ערך שלילי). |
| שֶׁל | אחד עשר | הצפה | זה מוגדר אם תוצאת המספר השלם היא מספר חיובי גדול מדי או מספר שלילי קטן מדי (למעט הסימן-bit) כדי להתאים לאופרנד היעד; ניקה אחרת. דגל זה מציין תנאי גלישה עבור אריתמטיקה של מספר שלם (השלמה של שניים). |
| DF | 10 | כיוון | זה מוגדר אם הוראות מחרוזת הכיוון פועלות (הגדלה או הקטנה). |
| תְעוּדַת זֶהוּת | עשרים ואחת | זיהוי | הוא מוגדר אם יכולת השינוי מציינת את נוכחות הוראת ה-CPUID. |
בנוסף לשמונה עשר האוגרים של 64 סיביות שצוינו בעבר, לארכיטקטורת x64 µP יש שמונה אוגרים ברוחב של 80 סיביות עבור אריתמטיקה של נקודה צפה. שמונת האוגרים הללו יכולים לשמש גם כאוגרי MMX (עיין בדיון הבא). ישנם גם שישה עשר אוגרים של 128 סיביות עבור XMM (עיין בדיון הבא).
זה לא הכל קשור לרשמים. ישנם עוד אוגרי x64 שהם אוגרי סגמנטים (לרוב אינם בשימוש ב-x64), אוגרי בקרה, אוגרי ניהול זיכרון, אוגרי באגים, אוגרי וירטואליזציה, אוגרי ביצועים שעוקבים אחר כל מיני פרמטרים פנימיים (התאמות/החמצות של מטמון, מיקרו-אופס שבוצעו, תזמון , ועוד הרבה).
SIMD
SIMD ראשי תיבות של Single Instruction Multiple Data. משמעות הדבר היא שהוראת שפת הרכבה אחת יכולה לפעול על מספר נתונים בו-זמנית במיקרו-מעבד אחד. שקול את הטבלה הבאה:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | אחד עשר | 12 | 13 | 14 | חֲמֵשׁ עֶשׂרֵה | 16 |
| = | 10 | 12 | 14 | 16 | 18 | עשרים | 22 | 24 |
בטבלה זו מתווספים שמונה זוגות של מספרים במקביל (באותו זמן) כדי לתת שמונה תשובות. הוראת שפת assembly אחת יכולה לבצע את שמונה תוספות המספרים השלמים המקבילים באוגרי MMX. דבר דומה ניתן לעשות עם אוגרי XMM. אז יש הוראות MMX עבור מספרים שלמים והוראות XMM עבור צפים.
6.32 מפת זיכרון וה-x64
כאשר מצביע ההוראות (מונה תוכנית) כולל 64 סיביות, המשמעות היא שניתן לטפל ב-264 = 1.844674407 x 1019 מיקומי בתים בזיכרון. בהקסדצימלי, מיקום הבתים הגבוה ביותר הוא FFFF,FFFF,FFFF,FFFF16. שום מחשב רגיל היום לא יכול לספק שטח זיכרון (שלם) כה גדול. אז, מפת זיכרון מתאימה למחשב x64 היא כדלקמן:

שים לב שלפער בין 0000,8000,0000,000016 ל-FFFF,7FFF,FFFF,FFFF16 אין מיקומי זיכרון (ללא מאגר זיכרון RAM). זהו הבדל של FFFF,0000,0000,000116 שהוא די גדול. לחצי הקנוני הגבוה יש את מערכת ההפעלה, בעוד שבחצי הקנוני הנמוך יש את תוכניות המשתמש (יישומים) והנתונים. מערכת ההפעלה מורכבת משני חלקים: UEFI קטן (BIOS) וחלק גדול שנטענים מהכונן הקשיח. הפרק הבא מדבר יותר על מערכות ההפעלה המודרניות. שימו לב לדמיון עם מפת הזיכרון הזו ושל Commodore-64 כאשר 64KB אולי נראה כמו הרבה זיכרון.
בהקשר זה, מערכת ההפעלה נקראת בערך 'הליבה'. הקרנל דומה לקרנל של מחשב Commodore-64, אבל יש לו הרבה יותר תתי שגרות.
ה-endianness עבור x64 הוא little endian, מה שאומר שעבור מיקום, הכתובת התחתונה מצביעה על בייט התוכן התחתון בזיכרון.
6.33 מצבי כתובת Assembly Language עבור x64
מצבי כתובת הם הדרכים שבהן הוראה יכולה לגשת לאוגרי µP ולזיכרון (כולל אוגרי היציאות הפנימיים). ל-x64 יש מצבי כתובת רבים, אך רק מצבי הכתובת הנפוצים מטופלים כאן. התחביר הכללי להוראה כאן הוא:
יעד אופקוד, מקור
המספרים העשרוניים נכתבים ללא שום קידומת או סיומת. עם ה-6502, המקור מרומז. ל-x64 יש יותר קודי הפעלה מאשר ל-6502, אבל לחלק מהקודים יש את אותה זיכרון. הוראות x64 הבודדות הן באורך משתנה וגודלן יכול לנוע בין 1 ל-15 בתים. מצבי הכתובת הנפוצים הם כדלקמן:
מצב פנייה מיידית
כאן, אופרנד המקור הוא ערך ממשי ולא כתובת או תווית. דוגמה (קרא את התגובה):
ADD EAX, 14 ; הוסף עשרוני 14 עד 32 סיביות EAX של 64 סיביות RAX, התשובה נשארת ב-EAX (יעד)
הירשם למצב רישום כתובת
דוגמא:
ADD R8B, AL ; הוסף 8 סיביות AL של RAX ל-R8B של 64 סיביות R8 - התשובות נשארות ב-R8B (יעד)
מצב כתובת עקיף ומוסף באינדקס
כתובת עקיפה עם ה-6502 µP פירושה שלמיקום הכתובת הנתונה בהוראה יש את הכתובת (המצביע) האפקטיבית של המיקום הסופי. דבר דומה קורה עם x64. כתובת אינדקס עם 6502 µP פירושה שהתוכן של אוגר µP מתווסף לכתובת הנתונה בהוראה לקבל את הכתובת האפקטיבית. דבר דומה קורה עם x64. כמו כן, עם ה-x64, ניתן להכפיל את תוכן המאגר ב-1 או 2 או 4 או 8 לפני הוספתו לכתובת הנתונה. הוראת ה-mov (העתק) של ה-x64 יכולה לשלב גם כתובת עקיפה וגם כתובת אינדקס. דוגמא:
MOV R8W, 1234[8*RAX+RCX] ; העבר מילה בכתובת (8 x RAX + RCX) + 1234
כאן, ל-R8W יש את 16 הסיביות הראשונים של R8. הכתובת הנתונה היא 1234. לרגיסטר RAX יש מספר של 64 סיביות המוכפל ב-8. התוצאה מתווספת לתוכן של אוגר 64 סיביות RCX. תוצאה שנייה זו מתווספת לכתובת הנתונה שהיא 1234 כדי לקבל את הכתובת האפקטיבית. המספר במיקום הכתובת האפקטיבית מועבר (מועתק) למקום הראשון של 16 סיביות (R8W) של האוגר R8, ומחליף את כל מה שהיה שם. שימו לב לשימוש בסוגריים המרובעים. זכור כי מילה ב-x64 היא ברוחב של 16 סיביות.
כתובת יחסית RIP
עבור 6502 µP, הכתובת היחסית משמשת רק עם הוראות סניף. שם, האופרנד היחיד של ה-opcode הוא היסט שמתווסף או מופחת לתוכן של ה-Programme Counter עבור כתובת ההוראה האפקטיבית (לא כתובת הנתונים). דבר דומה קורה עם x64 שבו נקרא מונה התוכניות בתור Instruction Pointer. ההוראה עם x64 לא חייבת להיות רק הוראת ענף. דוגמה לכתובת RIP יחסית היא:
MOV AL, [RIP]
ל-AL של RAX יש מספר חתום של 8 סיביות שמתווסף או מופחת מהתוכן ב-RIP (מצביע הוראות 64 סיביות) כדי להצביע על ההוראה הבאה. שים לב שהמקור והיעד מוחלפים באופן חריג בהוראה זו. שימו לב גם לשימוש בסוגריים המרובעים המתייחסים לתוכן של RIP.
6.34 הוראות נפוצות של x64
בטבלה הבאה * פירושו סיומות אפשריות שונות של תת-קבוצה של קודים:
| טבלה 6.34.1 הוראות נפוצות ב-x64 |
|
|---|---|
| Opcode | מַשְׁמָעוּת |
| MOV | העבר (העתק) אל/מ/בין זיכרון לרשמים |
| CMOV* | מהלכים שונים על תנאי |
| XCHG | לְהַחלִיף |
| BSWAP | החלפת בתים |
| PUSH/POP | שימוש בערימה |
| ADD/ADC | הוסף/עם נשיאה |
| SUB/SBC | הורידו/עם נשיאה |
| MUL/IMUL | הכפל/ללא סימן |
| DIV/IDIV | חלוקה/לא חתום |
| INC/DEC | הגדלה/הקטנה |
| NEG | לִשְׁלוֹל |
| CMP | לְהַשְׁווֹת |
| AND/OR/XOR/NOT | פעולות ביטוויזיות |
| SHR/SAR | העבר ימינה לוגי/אריתמטי |
| SHL/SAL | העבר שמאלה לוגית/אריתמטית |
| ROR/תפקיד | סובב ימינה/שמאלה |
| RCR/RCL | סובב ימינה/שמאלה דרך קצה הנשיאה |
| BT/BTS/BTR | בדיקת סיביות/וקבע/ואיפוס |
| JMP | קפיצה ללא תנאי |
| JE/JNE/JC/JNC/J* | קפוץ אם שווה/לא שווה/ לשאת/לא לשאת/הרבה אחרים |
| ללכת / ללכת / ללכת | לולאה עם ECX |
| התקשר/וחזר | תת שגרת שיחה/החזרה |
| לא | אין ניתוח |
| CPUID | מידע על המעבד |
ל-x64 יש הוראות כפל וחלק. יש לו מעגלי חומרה כפל וחילוק ב-µP שלו. ל-6502 µP אין מעגלי חומרה כפל וחילוק. מהיר יותר לבצע את הכפל והחילוק לפי חומרה מאשר לפי תוכנה (כולל הסטת ביטים).
הוראות מחרוזת
ישנן מספר הוראות מחרוזת, אך היחידה שתידון כאן היא הוראת MOVS (עבור מחרוזת העברה) להעתקת מחרוזת שמתחילה בכתובת C000 ח . כדי להתחיל בכתובת C100 ח , השתמש בהוראות הבאות:
MOVS [C100H], [C000H]
שימו לב לסיומת H עבור הקסדצימלי.
6.35 בלולאה ב-x64
ל-6502 µP יש הוראות ענף ללולאה. הוראת סניף קופצת למיקום כתובת שיש לו את ההוראה החדשה. מיקום הכתובת עשוי להיקרא 'לולאה'. ל-x64 יש הוראות LOOP/LOOPE/LOOPNE ללולאה. אין לבלבל את מילות השפה השמורה הללו עם התווית 'לולאה' (ללא המרכאות). ההתנהגות היא כדלקמן:
LOOP מוריד את ECX ובודק אם ECX אינו אפס. אם התנאי הזה (אפס) מתקיים, הוא קופץ לתווית שצוינה. אחרת, זה נופל (המשך עם שאר ההוראות בדיון הבא).
LOOPE מוריד את ECX ובודק שה-ECX אינו אפס (יכול להיות 1 למשל) ו-ZF מוגדר (ל-1). אם התנאים הללו מתקיימים, הוא קופץ על התווית. אחרת, זה נופל.
LOOPNE מוריד את ECX ובודק ש-ECX אינו אפס ו-ZF אינו מוגדר (כלומר, להיות אפס). אם התנאים הללו מתקיימים, הוא קופץ לתווית. אחרת, זה נופל.
עם x64, אוגר RCX או חלקי המשנה שלו כמו ECX או CX, מכילים את המספר השלם המונה. עם הוראות ה-LOOP, המונה בדרך כלל סופר לאחור, ויורד ב-1 עבור כל קפיצה (לולאה). בקטע קוד הלולאה הבא, המספר בפנקס ה-EAX גדל מ-0 ל-10 בעשר חזרות בעוד המספר ב-ECX סופר (יורד) פי 10 (קרא את ההערות):
MOV EAX, 0 ;
MOV ECX, 10; סופרים לאחור 10 פעמים כברירת מחדל, פעם אחת עבור כל איטרציה
תווית:
INC EAX ; הגדל את EAX כגוף הלולאה
תווית LOOP ; הפחת את EAX, ואם EAX אינו אפס, בצע מחדש את גוף הלולאה מ-'label:'
קידוד הלולאה מתחיל מ'תווית:'. שימו לב לשימוש במעי הגס. קידוד הלולאה מסתיים ב'תווית LOOP' האומרת הקטנת EAX. אם התוכן שלו אינו אפס, חזור להוראה שאחרי 'תווית:' ובצע מחדש כל הוראה (כל הוראות הגוף) שמגיעות כלפי מטה עד ל'תווית LOOP'. שים לב של'תווית' עדיין יכול להיות שם אחר.
6.36 קלט/פלט של x64
חלק זה של הפרק עוסק בשליחת הנתונים ליציאת פלט (פנימית) או בקבלת הנתונים מיציאת קלט (פנימית). לערכת השבבים יש יציאות שמונה סיביות. ניתן להתייחס לכל שתי יציאות 8 סיביות עוקבות כאל יציאת 16 סיביות, וכל ארבע יציאות רצופות יכולות להיות יציאת 32 סיביות. באופן זה, המעבד יכול להעביר 8, 16 או 32 סיביות להתקן חיצוני או ממנו.
ניתן להעביר את המידע בין המעבד ליציאה פנימית בשתי דרכים: באמצעות מה שמכונה קלט/פלט ממופה זיכרון או שימוש במרחב כתובות קלט/פלט נפרד. הקלט/פלט ממופה זיכרון הוא כמו מה שקורה עם מעבד 6502 שבו כתובות היציאה הן למעשה חלק מכל מרחב הזיכרון. במקרה זה, כאשר שולחים את הנתונים למיקום כתובת מסוים, הם עוברים ליציאה ולא לבנק זיכרון. ליציאות עשוי להיות מרחב כתובות I/O נפרד. במקרה אחרון זה, לכל בנק הזיכרון יש את הכתובות שלהם מאפס. יש טווח כתובות נפרד מ-0000H ל-FFFF16. אלה משמשים את היציאות בערכת השבבים. לוח האם מתוכנת על מנת לא לבלבל בין קלט/פלט ממופה זיכרון ומרחב כתובות קלט/פלט נפרד.
קלט/פלט ממופת זיכרון
עם זה, היציאות נחשבות כמיקומי זיכרון, והאופקודים הרגילים לשימוש בין הזיכרון ל- µP משמשים להעברת הנתונים בין µP ליציאות. אז כדי להעביר בייט מיציאה בכתובת F000H לאגר µP RAX:EAX:AX:AL, בצע את הפעולות הבאות:
MOV AL, [F000H]
ניתן להעביר מחרוזת מהזיכרון ליציאה ולהיפך. דוגמא:
MOVS [F000H], [C000H] ; המקור הוא C000H, והיעד הוא יציאה ב-F000H.
מרחב כתובות קלט/פלט נפרד
עם זה, יש להשתמש בהוראות המיוחדות לקלט ופלט.
העברת פריטים בודדים
פנקס המעבד להעברה הוא RAX. למעשה, זה RAX:EAX עבור מילה כפולה, RAX:EAX:AX עבור מילה, ו-RAX:EAX:AX:AL עבור בייט. לכן, כדי להעביר בייט מיציאה ב-FFF0h, אל RAX:EAX:AX:AL, הקלד את הדברים הבאים:
IN AL, [FFF0H]
להעברה הפוכה, הקלד את הדברים הבאים:
OUT [FFF0H], AL
לכן, עבור פריטים בודדים, ההוראות הן IN ו-OUT. ניתן לתת את כתובת היציאה גם בפנקס RDX:EDX:DX.
העברת מחרוזות
ניתן להעביר מחרוזת מהזיכרון ליציאת ערכת שבבים ולהיפך. כדי להעביר מחרוזת מיציאה בכתובת FFF0H לזיכרון, התחל ב-C100H, הקלד:
INS [ESI], [DX]
שיש לו אותה השפעה כמו:
INS [EDI], [DX]
המתכנת צריך לשים את כתובת היציאה של שני בתים של FFF0H באוגר RDX:EDX:Dx, ועליו לשים את כתובת שני בתים של C100H באוגר RSI:ESI או RDI:EDI. להעברה הפוכה, בצע את הפעולות הבאות:
INS [DX], [ESI]
שיש לו אותה השפעה כמו:
INS [DX], [EDI]
6.37 הערימה ב-x64
כמו מעבד 6502, גם למעבד x64 יש ערימה ב-RAM. הערימה עבור x64 יכולה להיות 2 16 = 65,536 בתים או שהוא יכול להיות 2 32 = אורך 4,294,967,296 בתים. זה גם גדל כלפי מטה. כאשר התוכן של אוגר נדחף אל המחסנית, המספר במצביע מחסנית RSP מצטמצם ב-8. זכור שכתובת זיכרון עבור x64 היא ברוחב של 64 סיביות. הערך במצביע המחסנית ב-µP מצביע על המיקום הבא בערימה ב-RAM. כאשר התוכן של אוגר (או ערך באופרנד אחד) מופץ מהמחסנית לתוך אוגר, המספר במצביע מחסנית RSP גדל ב-8. מערכת ההפעלה מחליטה את גודל המחסנית והיכן היא מתחילה ב-RAM וגדל כלפי מטה. זכרו שמחסנית היא מבנה Last-In-First-Out (LIFO) אשר גדל כלפי מטה ומתכווץ כלפי מעלה במקרה זה.
כדי לדחוף את התוכן של אוגר µP RBX לערימה, בצע את הפעולות הבאות:
PUSH RBX
כדי להחזיר את הערך האחרון בערימה אל RBX, בצע את הפעולות הבאות:
POP RBX
6.38 נוהל ב-x64
תת-השגרה ב-x64 נקראת 'פרוצדורה'. הערימה משמשת כאן יותר ממה שהיא משמשת עבור 6502 µP. התחביר עבור הליך x64 הוא:
proc_name:
גוף ההליך
…
ימין
לפני שתמשיך, שים לב שהקודים והתוויות עבור תת שגרת x64 (הוראות שפת הרכבה באופן כללי) אינם תלויי רישיות. כלומר proc_name זהה ל-PROC_NAME. בדומה ל-6502, השם של שם הפרוצדורה (תווית) מתחיל בתחילת שורה חדשה בעורך הטקסט של שפת האסמבלי. זה מלווה בנקודתיים ולא ברווח ו-opcode כמו ב-6502. גוף תת-השגרה עוקב אחריו, ומסתיים ב-RTS ולא ב-RTS כמו ב-6502 µP. כמו ב-6502, כל הוראה בגוף, כולל RET, לא מתחילה בתחילת הקו שלה. שים לב שתווית כאן יכולה להיות באורך של יותר מ-8 תווים. כדי לקרוא להליך זה, מלמעלה או מתחת להליך המוקלד, בצע את הפעולות הבאות:
CALL proc_name
עם 6502, שם התווית הוא רק הקלדה להתקשרות. עם זאת, כאן, המילה השמורה 'CALL' או 'call' מוקלדת, ואחריה שם הפרוצדורה (תת שגרה) אחרי רווח.
כאשר עוסקים בהליכים, יש בדרך כלל שני פרוצדורות. הליך אחד קורא לשני. הפרוצדורה שמתקשרת (יש לה את הוראת הקריאה) נקראת 'המתקשר', והפרוצדורה שנקראת נקראת 'הקוראת'. יש מוסכמה (כללים) שצריך לפעול לפיה.
חוקי המתקשר
על המתקשר להקפיד על הכללים הבאים בעת הפעלת תת שגרת:
1. לפני קריאה לשגרת משנה, על המתקשר לשמור את התוכן של אוגרים מסוימים שמיועדים כמתקשר נשמר למחסנית. הרגיסטרים שנשמרו על ידי המתקשר הם R10, R11 וכל רגיסטרים שהפרמטרים מוכנסים אליהם (RDI, RSI, RDX, RCX, R8, R9). אם יש לשמר את התוכן של אוגרים אלה לאורך שיחת המשנה, דחף אותם לערימה במקום לשמור ב-RAM. אלה חייבים להיעשות מכיוון שהנרשמים צריכים לשמש את הנמען כדי למחוק את התוכן הקודם.
2. אם הפרוצדורה היא להוסיף שני מספרים למשל, שני המספרים הם הפרמטרים שיש להעביר לערימה. כדי להעביר את הפרמטרים לתת-השגרה, הכנס שישה מהם לתוך האוגרים הבאים לפי הסדר: RDI, RSI, RDX, RCX, R8, R9. אם יש יותר משישה פרמטרים לשגרת המשנה, דחפו את השאר על הערימה בסדר הפוך (כלומר, הפרמטר האחרון ראשון). מכיוון שהמחסנית גדלה למטה, הראשון מבין הפרמטרים הנוספים (באמת הפרמטר השביעי) מאוחסן בכתובת הנמוכה ביותר (היפוך הפרמטרים הזה שימש היסטורית כדי לאפשר את העברת הפונקציות (תתי השגרות) עם מספר משתנה של פרמטרים).
3. כדי לקרוא לתת-השגרה (הליך), השתמש בהוראת הקריאה. הוראה זו ממקמת את כתובת ההחזרה על גבי הפרמטרים על המחסנית (המיקום הנמוך ביותר) והסניפים לקוד תת-השגרה.
4. לאחר שתת-השגרה חוזרת (כלומר מיד לאחר הוראת השיחה), על המתקשר להסיר כל פרמטר נוסף (מעבר לשישה שמאוחסנים ברגיסטרים) מהמחסנית. פעולה זו משחזרת את הערימה למצבה לפני ביצוע הקריאה.
5. המתקשר יכול לצפות למצוא את ערך ההחזרה (הכתובת) של תת-השגרה במאגר RAX.
6. המתקשר משחזר את התוכן של האוגרים שנשמרו על ידי המתקשר (R10, R11, וכל מה שנמצא ברשמים העוברים פרמטרים) על ידי הוצאתם מהמחסנית. המתקשר יכול להניח ששום אוגרים אחרים לא השתנו על ידי תת-השגרה.
בשל האופן שבו בנויה אמנת השיחות, זה בדרך כלל המקרה שחלק (או רוב) השלבים הללו לא יבצעו שינויים בערימה. לדוגמה, אם יש שישה פרמטרים או פחות, שום דבר לא נדחף אל הערימה בשלב זה. באופן דומה, המתכנתים (והמהדרים) בדרך כלל שומרים את התוצאות שחשובות להם מחוץ לרישומי המתקשרים שנשמרו בשלבים 1 ו-6 כדי למנוע את הדחיפות והקפיצות העודפות.
ישנן שתי דרכים נוספות להעביר את הפרמטרים לתת-שגרה, אך אלה לא יטופלו בקורס קריירה מקוון זה. אחד מהם משתמש בערימה עצמה במקום ברגיסטרים למטרות כלליות.
חוקי ה-Callee
ההגדרה של תת-השגרה הנקראת צריכה לעמוד בכללים הבאים:
1. הקצו את המשתנים המקומיים (משתנים שפותחו בתוך הפרוצדורה) באמצעות הרגיסטרים או יצירת מקום על המחסנית. נזכיר שהערימה גדלה כלפי מטה. לכן, כדי לפנות מקום בחלק העליון של הערימה, יש להקטין את מצביע הערימה. הכמות שבה מופחת מצביע הערימה תלוי במספר הדרוש של משתנים מקומיים. לדוגמה, אם נדרשים ציפה מקומית ואורך מקומי (סה'כ 12 בתים), יש להקטין את מצביע המחסנית ב-12 כדי לפנות מקום למשתנים המקומיים הללו. בשפה ברמה גבוהה כמו C, זה אומר להכריז על המשתנים מבלי להקצות (לאתחל) את הערכים.
2. לאחר מכן, יש לשמור את הערכים של כל הרגיסטרים שהם ה- Callee-Shield המיועד (אוגרי מטרה כלליים שאינם נשמרים על ידי המתקשר) המשמשים את הפונקציה. כדי לשמור את הרשמים, דחפו אותם על הערימה. האוגרים שנשמרו על ידי הקורא הם RBX, RBP ו-R12 עד R15 (RSP נשמר גם על ידי מוסכמות השיחה, אך אין צורך לדחוף אותם על הערימה במהלך שלב זה).
לאחר ביצוע שלוש הפעולות הללו, הפעולה בפועל של תת-השגרה עשויה להמשיך. כאשר תת-השגרה מוכנה לחזור, כללי מוסכמות השיחה ממשיכים.
3. כאשר תת-השגרה מסתיימת, יש למקם את ערך ההחזרה של תת-השגרה ב-RAX אם היא עדיין לא קיימת.
4. על תת-השגרה לשחזר את הערכים הישנים של כל אוגרים שנשמרו על ידי קורא (RBX, RBP ו-R12 עד R15) ששונו. תוכן הרישום משוחזר על ידי הוצאתם מהמחסנית. שימו לב שיש להקפיץ את הרשמים בסדר הפוך שהם נדחפו.
5. לאחר מכן, אנו מחלקים את המשתנים המקומיים. הדרך הקלה ביותר לעשות זאת היא להוסיף ל-RSP את אותו הכמות שהופחתה ממנו בשלב 1.
6. לבסוף, אנו חוזרים אל המתקשר על ידי ביצוע הוראת ret. הוראה זו תמצא ותסיר את כתובת ההחזרה המתאימה מהמחסנית.
דוגמה לגוף של תת שגרת מתקשר להתקשרות לשגרת משנה אחרת שהיא 'myFunc' היא כדלקמן (קראו את ההערות):
; רוצה לקרוא לפונקציה 'myFunc' שלוקחת שלושה
; פרמטר מספר שלם. הפרמטר הראשון הוא ב- RAX.
; פרמטר שני הוא הקבוע 456. שלישי
; הפרמטר נמצא במיקום הזיכרון 'משתנה'
לדחוף rdi; rdi יהיה param, אז שמור אותו
; long retVal = myFunc (x, 456, z);
מוב רדי , רקס ; שים פרמטר ראשון ב-RDI
מוב רסי, 456; שים פרמטר שני ב-RSI
mov rdx , [variabl]; שים פרמטר שלישי ב-RDX
התקשר ל-myFunc; לקרוא לפונקציה
פופ rdi ; שחזר ערך RDI שמור
; ערך ההחזרה של myFunc זמין כעת ב-RAX
דוגמה לפונקציית callee (myFunc) היא (קראו את ההערות):
myFunc:
; ∗∗∗ פרולוג תתי שגרה רגיל ∗∗∗
תת rsp, 8; מקום למשתנה מקומי של 64 סיביות (תוצאה) באמצעות ה-opcode 'משנה'.
לדחוף rbx; שמור callee-save registers
לדחוף rbp; שניהם ישמשו את myFunc
; ∗∗∗ תת שגרה גוף ∗∗∗
מוב רקס , רדי ; פרמטר 1 ל-RAX
מוב רבפ , רסי ; פרמטר 2 ל-RBP
mov rbx , rdx ; פרמטר 3 ל-rb x
mov [rsp + 1 6], rbx; הכניסו rbx למשתנה מקומי
הוסף [rsp + 1 6], rbp; הוסף rbp למשתנה מקומי
mov רקס, [rsp +16]; העבר תוכן של משתנה מקומי ל- RAX
; (ערך החזר/תוצאה סופית)
; ∗∗∗ אפילוג משנה סטנדרטי ∗∗∗
פופ rbp; לשחזר את רישומי שמירת השיחות
פופ rbx ; היפוך של דחיפה
הוסף rsp, 8; ביטול הקצאה של משתנים מקומיים. 8 פירושו 8 בתים
ret ; פופ ערך עליון מהערימה, קפוץ לשם
6.39 פסיקות וחריגים עבור x64
המעבד מספק שני מנגנונים להפסקת ביצוע התוכנית, פסיקות וחריגים:
- פסיקה היא אירוע אסינכרוני (יכול לקרות בכל עת) המופעל בדרך כלל על ידי התקן קלט/פלט.
- חריג הוא אירוע סינכרוני (קורה כאשר הקוד מבוצע, מתוכנת מראש, בהתבסס על התרחשות כלשהי) שנוצר כאשר המעבד מזהה תנאי מוגדר מראש אחד או יותר בזמן ביצוע פקודה. מצוינים שלושה סוגים של חריגים: תקלות, מלכודות והפסקות.
המעבד מגיב להפסקות ולחריגים בעצם באותו אופן. כאשר מאותתים על הפרעה או חריגה, המעבד עוצר את ביצוע התוכנית או המשימה הנוכחית ועובר לנוהל מטפל שנכתב במיוחד כדי לטפל במצב ההפרעה או החריגה. המעבד ניגש להליך המטפל דרך ערך בטבלת מתארי הפסקות (IDT). כאשר המטפל השלים את הטיפול בהפרעה או החריגה, בקרת התוכנית מוחזרת לתוכנית או למשימה שהופסקה.
מערכת ההפעלה, מנהלי ההתקן ו/או מנהלי ההתקן מטפלים בדרך כלל בהפסקות ובחריגים ללא תלות בתוכניות היישום או המשימות. עם זאת, תוכניות היישום יכולות לגשת למטפלי הפסיקות והחריגים המשולבים במערכת הפעלה או להפעיל אותה באמצעות הקריאות בשפת ה-Assembly.
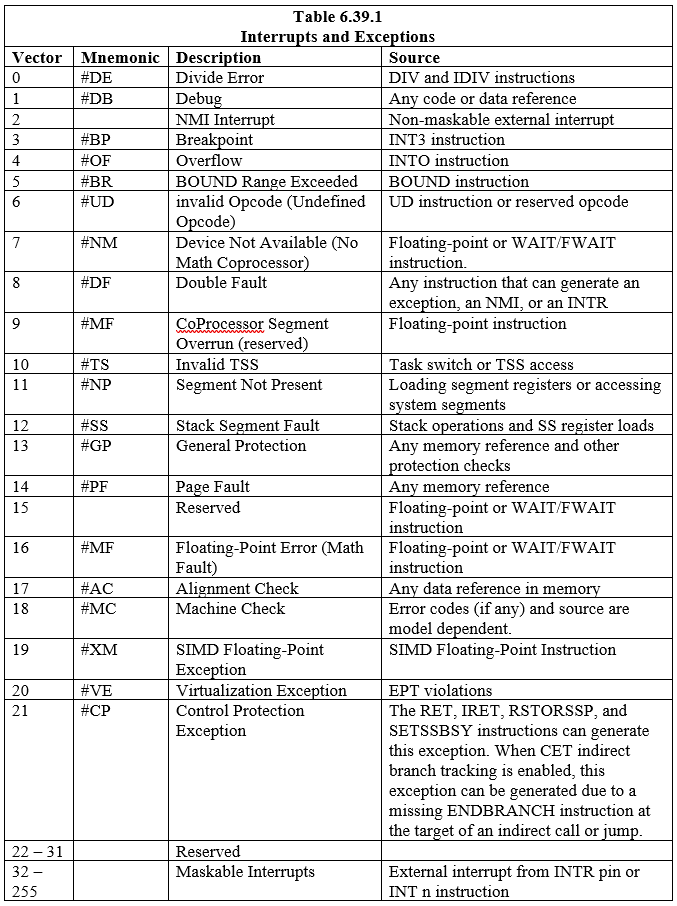
18 (18) פסיקות וחריגים מוגדרים מראש, המשויכים לערכים ב-IDT, מוגדרים. ניתן גם לבצע מאתיים עשרים וארבע (224) פסיקות בהגדרת משתמש ולשייך לטבלה. כל פסיקה וחריגה ב-IDT מזוהה עם מספר הנקרא 'וקטור'. טבלה 6.39.1 מפרטת את ההפסקות והחריגים עם ערכים ב-IDT והווקטורים שלהם. וקטורים 0 עד 8, 10 עד 14 ו-16 עד 19 הם הפסיקות והחריגים שהוגדרו מראש. הווקטורים 32 עד 255 מיועדים לפסיקות המוגדרות בתוכנה (משתמש) אשר מיועדות להפסקות תוכנה או לפסיקות חומרה הניתנות למסיכה.
כאשר המעבד מזהה הפרעה או חריגה, הוא עושה אחת מהפעולות הבאות:
- בצע קריאה מרומזת לנוהל מטפל
- בצע קריאה מרומזת למשימה של מטפל
6.4 היסודות של ארכיטקטורת מחשב 64 סיביות של ARM
ארכיטקטורות ARM מגדירות משפחה של מעבדי RISC המתאימים לשימוש במגוון רחב של יישומים. ARM היא ארכיטקטורת טעינה/אחסון הדורשת טעינת הנתונים מהזיכרון לרישום לפני שניתן לבצע איתה עיבוד כלשהו כגון פעולת ALU (Arithmetic Logic Unit). הוראה לאחר מכן מאחסנת את התוצאה בחזרה לזיכרון. למרות שזה עשוי להיראות כמו צעד אחורה מארכיטקטורות x86 ו-x64, הפועלות ישירות על האופרנדים בזיכרון בהוראה אחת (באמצעות אוגרי מעבד, כמובן), גישת הטעינה/אחסון, בפועל, מאפשרת מספר פעולות עוקבות להתבצע במהירות גבוהה על אופרנד ברגע שהוא נטען לתוך אחד מהרבה אוגרי מעבדים. למעבדי ARM יש את האפשרות של מעט קצה או קצה גדול. הגדרת ברירת המחדל של ARM 64 היא little-endian שהיא התצורה שבה משתמשים בדרך כלל במערכות ההפעלה. ארכיטקטורת ARM של 64 סיביות היא מודרנית והיא אמורה להחליף את ארכיטקטורת ARM של 32 סיביות.
הערה : כל הוראה עבור 64 סיביות ARM µP היא באורך 4 בתים (32 סיביות).
6.41 ערכת 64-Bit ARM Register
ישנם 31 מטרות כלליות של אוגרים של 64 סיביות עבור 64 סיביות ARM µP. התרשים הבא מציג את האוגרים לשימוש כללי וכמה אוגרים חשובים:
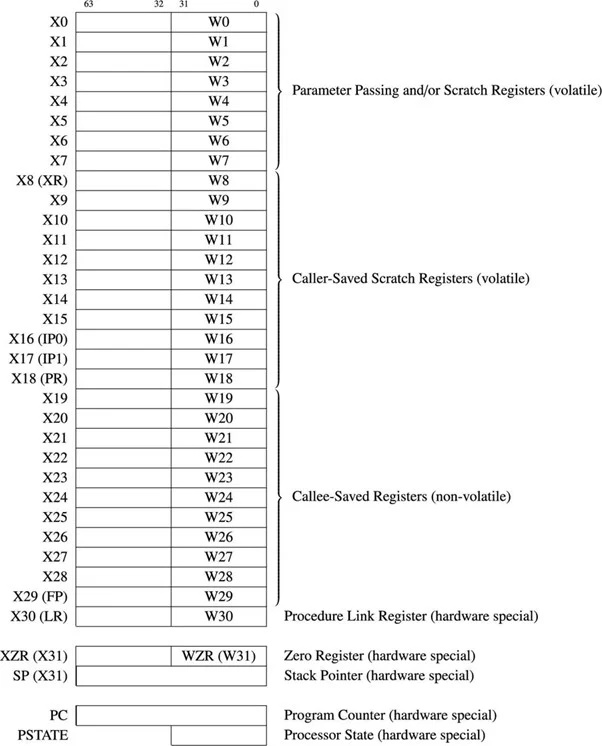
איור.4.11.1 מטרה כללית של 64 סיביות וכמה רישומים חשובים
האוגרים לשימוש כללי מכונים X0 עד X30. החלק הראשון של 32 סיביות עבור כל אוגר נקרא W0 עד W30. כאשר ההבדל בין 32 סיביות ל-64 סיביות אינו מודגש, נעשה שימוש בקידומת 'R'. לדוגמה, R14 מתייחס ל-W14 או X14.
ל-6502 µP יש מונה תוכניות של 16 סיביות והוא יכול לתת מענה ל-2 16 מיקומי בתים של זיכרון. ל-64 סיביות ARM µP יש מונה תוכניות של 64 סיביות ויכול לתת מענה לעד 2 64 = 1.844674407 x 1019 (למעשה 18,446,744,073,709,551,616) מיקומי בייט זיכרון. מונה התוכנית מכיל את הכתובת של ההוראה הבאה שתתבצע. אורך ההוראה של ARM64 או AArch64 הוא בדרך כלל ארבעה בתים. המעבד מגדיל אוטומטית את האוגר הזה בארבע לאחר שליפת כל הוראה מהזיכרון.
אוגר ה-Stack Pointer או SP אינו בין 31 האוגרים למטרות כלליות. מצביע המחסנית של כל ארכיטקטורה מצביע על כניסת המחסנית האחרונה בזיכרון. עבור ARM-64, הערימה גדלה כלפי מטה.
ל-6502 µP יש רישום מצב מעבד של 8 סיביות. המקבילה ב-ARM64 נקראת ה- PSTATE register. אוגר זה מאחסן את הדגלים המשמשים לתוצאות הפעולות ולשליטה במעבד (µP). הוא ברוחב 32 סיביות. הטבלה הבאה נותנת את השמות, האינדקס והמשמעויות עבור הסיביות הנפוצות באוגר PSTATE:
| טבלה 6.41.1 דגלים PSTATE (ביטים) הנפוצים ביותר |
||
|---|---|---|
| סֵמֶל | קצת | מַטָרָה |
| M | 0-3 | מצב: רמת הרשאות הביצוע הנוכחית (USR, SVC וכן הלאה). |
| ט | 4 | אגודל: הוא מוגדר אם ערכת ההוראות T32 (אגודל) פעילה. אם ברור, ערכת הוראות ה-ARM פעילה. קוד המשתמש יכול להגדיר ולנקות סיביות זו. |
| ו | 9 | Endianness: הגדרת סיביות זו מאפשרת את מצב big-endian. אם הוא ברור, מצב ה- little-endian פעיל. ברירת המחדל היא מצב ה- little-endian. |
| ש | 27 | דגל רוויה מצטבר: הוא מוגדר אם, בשלב מסוים בסדרת פעולות, מתרחשת הצפה או רוויה |
| IN | 28 | דגל הצפה: הוא מוגדר אם הפעולה הביאה לגלישה חתומה. |
| ג | 29 | דגל נשיאה: זה מציין אם החיבור יצר נשיאה או החיסור יצר הלוואה. |
| עם | 30 | דגל אפס: הוא מוגדר אם התוצאה של פעולה היא אפס. |
| נ | 31 | דגל שלילי: הוא מוגדר אם התוצאה של פעולה שלילית. |
ל-ARM-64 µP יש אוגרים רבים אחרים.
SIMD
SIMD ראשי תיבות של Single Instruction, Multiple Data. משמעות הדבר היא שהוראת שפת הרכבה אחת יכולה לפעול על מספר נתונים בו-זמנית במיקרו-מעבד אחד. ישנם שלושים ושניים רגיסטרים ברוחב 128 סיביות לשימוש עם SIMD ופעולות נקודה צפה.
6.42 מיפוי זיכרון
RAM ו-DRAM הם שניהם זיכרונות גישה אקראית. DRAM איטי יותר בפעולה מ-RAM. DRAM זול יותר מ-RAM. אם יש יותר מ-32 גיגה-בייט (GB) של DRAM מתמשך בזיכרון, יהיו יותר בעיות בניהול זיכרון: 32 GB = 32 x 1024 x 1024 x 1024 בתים. עבור שטח זיכרון שלם שגדול בהרבה מ-32 ג'יגה-בייט, יש לשלב את ה-DRAM מעל 32 ג'יגה-בייט עם זיכרון RAM לניהול זיכרון טוב יותר. על מנת להבין את מפת הזיכרון של ARM-64, תחילה עליך להבין את מפת הזיכרון של 4GB עבור יחידת העיבוד המרכזית של ARM (CPU) של 32 סיביות. CPU פירושו µP. עבור מחשב 32 סיביות, השטח המרבי שניתן לכתובת בזיכרון הוא 2 32 = 4 x 2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4,294,967,296 = 4GB.
מפת זיכרון ARM של 32 סיביות
מפת הזיכרון עבור ARM 32 סיביות היא:

עבור מחשב 32 סיביות, הגודל המרבי של כל הזיכרון הוא 4GB. מהכתובת של 0GB לכתובת של 1GB הם מיקומי מערכת ההפעלה של ROM, זיכרון RAM ו-I/O. כל הרעיון של ROM OS, RAM וכתובות I/O דומה למצב של Commodore-64 עם מעבד 6502 אפשרי. ROM OS עבור Commodore-64 נמצא בקצה העליון של שטח הזיכרון. מערכת ההפעלה ה-ROM כאן גדולה בהרבה מזו של ה-Commodore-64, והיא נמצאת בתחילת כל מרחב הכתובות בזיכרון. בהשוואה למחשבים מודרניים אחרים, מערכת ההפעלה ROM כאן מלאה, במובן זה שהיא ניתנת להשוואה לכמות מערכת ההפעלה בכוננים הקשיחים שלהם. ישנן שתי סיבות עיקריות למערכת ההפעלה במעגלים המשולבים ב-ROM: 1) מעבדי ARM משמשים בעיקר במכשירים קטנים כמו סמארטפונים. כוננים קשיחים רבים גדולים יותר מסמארטפונים ומתקנים קטנים אחרים, 2) לצורך אבטחה. כאשר מערכת ההפעלה נמצאת בזיכרון לקריאה בלבד, היא לא יכולה להיפגם (חלקים יחליפו) על ידי האקרים. גם קטעי ה-RAM וקטעי הקלט/פלט גדולים מאוד בהשוואה לאלו של ה-Commodore-64.
כאשר הכוח מופעל עם מערכת ההפעלה ROM של 32 סיביות, מערכת ההפעלה חייבת להתחיל בכתובת (אתחול מ) הכתובת 0x00000000 או כתובת 0xFFFF0000 אם HiVECs מופעלים. לכן, כאשר הכוח מופעל לאחר שלב האיפוס, חומרת המעבד טוענת 0x00000000 או 0xFFFF0000 למונה התוכניות. הקידומת '0x' פירושה הקסדצימלי. כתובת האתחול של מעבדי ARMv8 64bit היא מימוש מוגדר. עם זאת, המחבר מייעץ למהנדס המחשבים להתחיל ב-0x00000000 או 0xFFFF0000 למען תאימות לאחור.
מ-1GB ל-2GB הוא הקלט/פלט הממופים. יש הבדל בין ה-I/O הממופת ל-I/O בלבד שנמצאים בין 0GB ל-1GB. עם I/O, הכתובת עבור כל יציאה קבועה כמו ב-Commodore-64. עם I/O ממופה, הכתובת עבור כל יציאה אינה בהכרח זהה עבור כל פעולה של המחשב (דינמית).
מ-2GB עד 4GB זה DRAM. זהו זיכרון ה-RAM הצפוי (או הרגיל). DRAM מייצג דינמי RAM, לא התחושה של כתובת משתנה במהלך פעולת המחשב אלא במובן שיש לרענן את הערך של כל תא ב-RAM הפיזי בכל פעימת שעון.
הערה :
- מ-0x0000,0000 ל-0x0000, FFFF הוא ROM OS.
- מ-0x0001,0000 ל-0x3FFF,FFFF, יכול להיות יותר ROM, לאחר מכן RAM, ולאחר מכן קצת I/O.
- מ-0x4000,0000 ל-0x7FFF,FFFF, מותר קלט/פלט נוסף ו/או קלט/פלט ממופה.
- מ-0x8000,0000 ל-0xFFFF, FFFF הוא ה-DRAM הצפוי.
המשמעות היא שה-DRAM הצפוי לא חייב להתחיל בגבול הזיכרון של 2GB, בפועל. למה המתכנת צריך לכבד את הגבולות האידיאליים כשאין מספיק מאגר RAM פיזיים המחוברים ללוח האם? הסיבה לכך היא שללקוח אין מספיק כסף עבור כל בנקי ה-RAM.
מפת זיכרון ARM של 36 סיביות
עבור מחשב ARM 64 סיביות, כל 32 הסיביות משמשות כדי לטפל בזיכרון כולו. עבור מחשב ARM 64 סיביות, ניתן להשתמש ב-36 הסיביות הראשונות כדי לטפל בזיכרון כולו, שבמקרה זה הוא 2 36 = 68,719,476,736 = 64GB. זה כבר הרבה זיכרון. המחשבים הרגילים כיום אינם זקוקים לכמות הזיכרון הזו. זה עדיין לא מגיע לטווח המקסימלי של זיכרון שניתן לגשת אליו על ידי 64 סיביות. מפת הזיכרון עבור 36 סיביות עבור מעבד ARM היא:
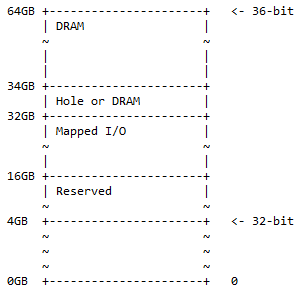
מהכתובת של 0GB לכתובת של 4GB היא מפת הזיכרון של 32 סיביות. 'שמור' פירושו לא נעשה בו שימוש והוא נשמר לשימוש עתידי. זה לא חייב להיות מאגרי זיכרון פיזיים שמוכנסים ללוח האם עבור החלל הזה. כאן, ל-DRAM ול-I/O ממופה יש את אותן משמעויות כמו למפת הזיכרון של 32 סיביות.
ניתן למצוא את המצב הבא בפועל:
- 0x1 0000 0000 - 0x3 FFFF FFFF; שמורות. 12GB של שטח כתובות שמור לשימוש עתידי.
- 0x4 0000 0000 – 0x7 FFFF FFFF; I/O ממופה. 16GB של שטח כתובות זמין עבור I/O ממופה דינמית.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; חור או DRAM. 2GB של שטח כתובות יכול להכיל אחת מהאפשרויות הבאות:
- חור כדי לאפשר את חלוקת התקן DRAM (כמתואר בדיון הבא).
- לְגִימָה.
- 0x8 8000 0000 – 0xF FFFF FFFF; לְגִימָה. 30GB של שטח כתובת עבור DRAM.
מפת זיכרון זו היא ערכת-על של מפת הכתובות של 32 סיביות, כאשר השטח הנוסף מפוצל כ-50% DRAM (1/2) עם חור אופציונלי בתוכו ו-25% שטח קלט/פלט ממופה ושטח שמור (1/4 ). 25% הנותרים (1/4) מיועדים למפת הזיכרון של 32 סיביות ½ + ¼ + ¼ = 1.
הערה : מ-32 סיביות ל-360 סיביות היא תוספת של 4 סיביות לצד המשמעותי ביותר של 36 סיביות.
מפת זיכרון של 40 סיביות
מפת הכתובות של 40 סיביות היא ערכת-על של מפת הכתובות של 36 סיביות ועוקבת אחר אותה תבנית של 50% DRAM של חור אופציונלי בה, 25% משטח קלט/פלט ממופה ושטח שמור, ושאר 25% מקום למפת הזיכרון הקודמת (36 סיביות). הדיאגרמה של מפת הזיכרון היא:
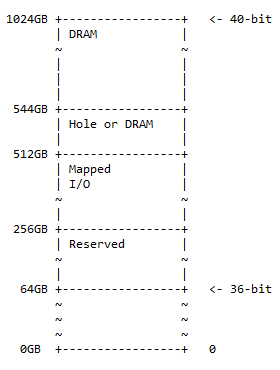
גודל החור הוא 544 - 512 = 32GB. ניתן למצוא את המצב הבא בפועל:
- 0x10 0000 0000 – 0x3F FFFF FFFF; שמורות. 192GB של שטח כתובות שמור לשימוש עתידי.
- 0x40 0000 0000 – 0x7F FFFF FFFF; ממופה. I/O 256GB של שטח כתובות זמין עבור I/O ממופה דינמית.
- 0x80 0000 0000 – 0x87 FFFF FFFF; חור או DRAM. 32GB של שטח כתובות יכול להכיל אחת מהאפשרויות הבאות:
- חור כדי לאפשר את חלוקת התקן DRAM (כמתואר בדיון הבא)
- לְגִימָה
- 0x88 0000 0000 – 0xFF FFFF FFFF; לְגִימָה. 480GB של שטח כתובות עבור DRAM.
הערה : מ-36 סיביות ל-40 סיביות היא תוספת של 4 סיביות לצד המשמעותי ביותר של 36 סיביות.
חור DRAM
במפת הזיכרון מעבר ל-32 סיביות, זה או חור DRAM או המשך של DRAM מלמעלה. כאשר מדובר בחור, יש להעריך זאת כדלקמן: חור DRAM מספק דרך לחלק התקן DRAM גדול לטווחי כתובות מרובים. חור ה-DRAM האופציונלי מוצע בתחילת גבול כתובת ה-DRAM הגבוה יותר. זה מאפשר סכימת פענוח מפושטת בעת חלוקת התקן DRAM בעל קיבולת גדולה על פני האזור התחתון של הכתובת הפיזית.
לדוגמה, חלק של 64GB DRAM מחולק לשלושה אזורים כאשר קיזוז הכתובות מתבצע על ידי חיסור פשוט בסיביות הכתובות בסדר גבוה באופן הבא:
| טבלה 6.42.1 דוגמה לחלוקת DRAM בנפח 64GB עם חורים |
|||
|---|---|---|---|
| כתובות פיזיות ב-SoC | לְקַזֵז | כתובת DRAM פנימית | |
| 2 GBytes (מפה 32 סיביות) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 GBytes (מפה 36 סיביות) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GBytes (מפה של 40 סיביות) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
מפות זיכרון ממוענות של 44 סיביות ו-48 סיביות עבור מעבדי ARM
נניח שלמחשב אישי יש 1024GB (= 1TB) זיכרון; זה יותר מדי זיכרון. וכך, מפות הזיכרון הממוענות של 44 סיביות ו-48 סיביות עבור מעבדי ARM עבור 16 TB ו- 256 TB, בהתאמה, הן רק הצעות לצרכי מחשב עתידיים. למעשה, הצעות אלו עבור מעבדי ARM עוקבות אחר אותה חלוקה של זיכרון לפי יחס כמו מפות הזיכרון הקודמות. כלומר: 50% DRAM עם חור אופציונלי בתוכו, 25% משטח I/O ממופה ושטח שמור, ושאר 25% השטח למפת הזיכרון הקודמת.
עדיין יש להציע את מפות הזיכרון הממוענות של 52 סיביות, 56 סיביות, 60 סיביות ו-64 סיביות עבור ARM 64 סיביות לעתיד הרחוק. אם המדענים באותו זמן עדיין מוצאים את החלוקה של 50:25:25 של כל שטח הזיכרון שימושי, הם ישמרו על היחס.
הערה : SoC קיצור של System-on-Chip המתייחס למעגלים בשבב µP שאחרת לא היו שם.
SRAM או Static Random Access Memory מהיר יותר מה-DRAM המסורתי יותר, אך דורש יותר שטח סיליקון. SRAM אינו דורש רענון. הקורא יכול לדמיין את זיכרון ה-RAM כ-SRAM.
6.43 מצבי כתובת שפת הרכבה עבור ARM 64
ARM היא ארכיטקטורת עומס/אחסון המחייבת טעינת הנתונים מהזיכרון לאגר מעבד לפני שניתן לבצע איתה עיבוד כלשהו כגון פעולת לוגיקה אריתמטית. הוראה לאחר מכן מאחסנת את התוצאה בחזרה לזיכרון. למרות שזה עשוי להיראות כמו צעד אחורה מה-x86 ומארכיטקטורות ה-x64 שלאחריו, הפועלות ישירות על האופרנדים בזיכרון בהוראה אחת, בפועל, גישת הטעינה/אחסון מאפשרת לבצע מספר פעולות עוקבות במהירות גבוהה על אופרנד ברגע שהוא נטען לאחד מרגרי המעבד הרבים.
לפורמט של שפת ההרכבה של ARM יש קווי דמיון והבדלים עם סדרת x64 (x86).
- לְקַזֵז : ניתן להוסיף קבוע בסימן למאגר הבסיס. ההיסט מוקלד כחלק מההוראה. לדוגמה: ldr x0, [rx, #10] טוען r0 עם המילה בכתובת r1+10.
- הירשם : ניתן להוסיף או לגרוע מהערך באוגר בסיס תוספת ללא סימן המאוחסנת באוגר. לדוגמה: ldr r0, [x1, x2] טוען את r0 עם המילה בכתובת x1+x2. ניתן לחשוב על כל אחד מהרגיסטרים כאוגר הבסיס.
- רישום מוקטן : תוספת באוגר מוזז שמאלה או ימינה במספר מוגדר של מיקומי סיביות לפני הוספת ערך אוגר הבסיס או מופחת ממנו. לדוגמה: ldr x0, [x1, x2, lsl #3] טוען את r0 במילה בכתובת r1+(r2×8). ההסטה יכולה להיות העברה לוגית שמאלה או ימינה (lsl או lsr) המכניסה אפס ביטים במיקומי הסיביות שהתפנו או הזזה אריתמטית ימינה (asr) המשכפלת את ביט הסימן במיקומים שהתפנו.
כאשר מעורבים שני אופרנדים, היעד מגיע לפני (בצד שמאל) המקור (יש כמה חריגים לכך). הקודים עבור שפת ההרכבה של ARM אינם רגישים לאותיות גדולות.
מצב כתובת ARM64 מיידי
דוגמא:
mov r0, #0xFF000000 ; טען את ערך 32 הסיביות FF000000h לתוך r0
ערך עשרוני הוא ללא 0x אך עדיין יש # לפניו.
הרשמה ישירה
דוגמא:
mov x0, x1 ; העתק את x1 ל-x0
הרשמה עקיפה
דוגמא:
str x0, [x3]; אחסן את x0 לכתובת ב-x3
הרשמה עקיפה עם Offset
דוגמאות:
ldr x0, [x1, #32]; טען r0 עם הערך בכתובת [r1+32]; r1 הוא אוגר הבסיס
str x0, [x1, #4]; אחסן את r0 לכתובת [r1+4]; r1 הוא אוגר הבסיס; המספרים הם בסיס 10
רישום עקיף עם קיזוז (מוגדל מראש)
דוגמאות:
ldr x0, [x1, #32]! ; טען r0 עם [r1+32] ועדכן את r1 ל-(r1+32)
str x0, [x1, #4]! ; אחסן את r0 ל-[r1+4] ועדכן את r1 ל-(r1+4)
שימו לב לשימוש ב'!' סֵמֶל.
רישום עקיף עם קיזוז (אחרי תוספת)
דוגמאות:
ldr x0, [x1], #32 ; טען [x1] ל-x0, ולאחר מכן עדכן את x1 ל-(x1+32)
str x0, [x1], #4 ; אחסן את x0 ל-[x1], ולאחר מכן עדכן את x1 ל-(x1+4)
רישום כפול בעקיפין
הכתובת של האופרנד היא הסכום של אוגר בסיס ואוגר מצטבר. שמות הרישום מוקפים בסוגריים מרובעים.
דוגמאות:
ldr x0, [x1, x2]; טען x0 עם [x1+x2]
str x0, [rx, x2]; אחסן את x0 עד [x1+x2]
מצב כתובת יחסית
במצב פנייה יחסי, ההוראה האפקטיבית היא ההוראה הבאה במונה התוכניות, בתוספת אינדקס. המדד יכול להיות חיובי או שלילי.
דוגמא:
ldr x0, [pc, #24]
משמעות הדבר היא אוגר העומס X0 עם המילה שעליה מצביע תוכן המחשב בתוספת 24.
6.44 כמה הוראות נפוצות עבור ARM 64
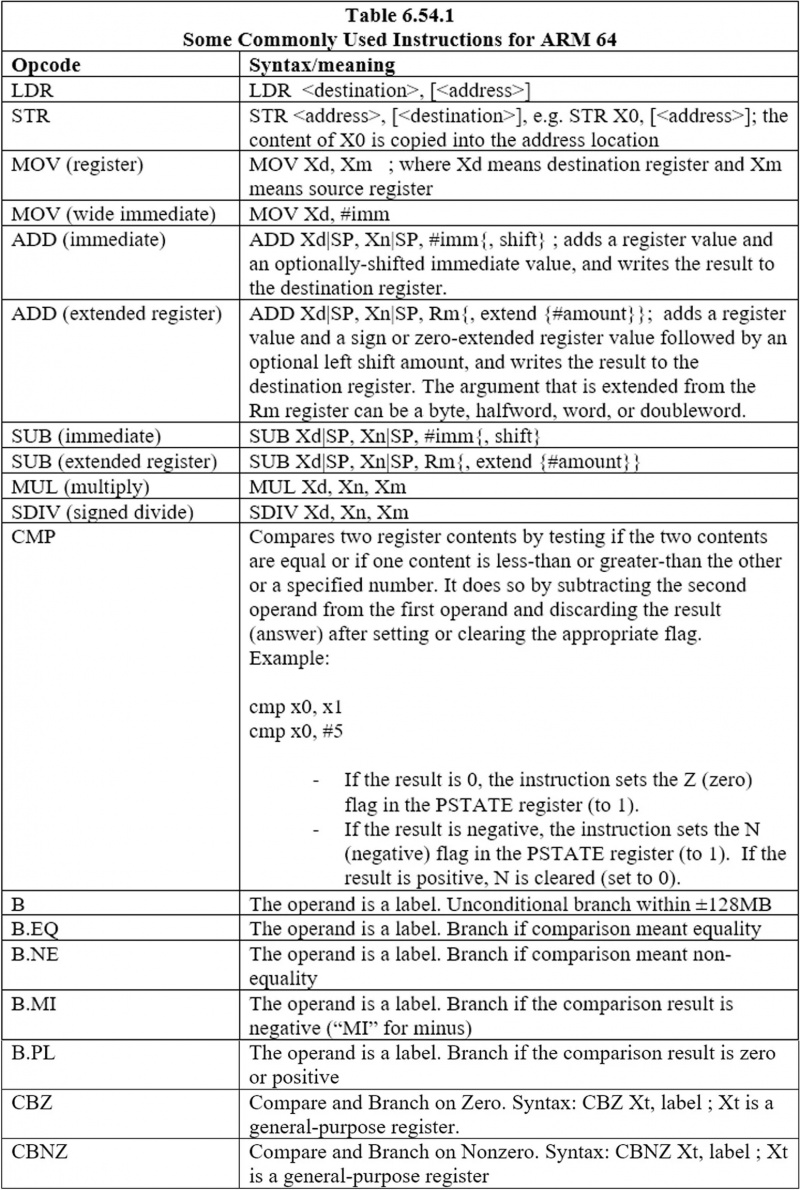
להלן ההוראות הנפוצות:
6.45 לולאה
אִיוּר
הקוד הבא ממשיך להוסיף את הערך באוגר X10 לערך ב-X9 עד שהערך ב-X8 הוא אפס. נניח שכל הערכים הם מספרים שלמים. הערך ב-X8 מופחת ב-1 בכל איטרציה:
לוּלָאָה:
CBZ X8, דלג
ADD X9, X9, X10; X9 הראשון הוא יעד והשני X9 הוא מקור
SUB X8, X8, #1 ; X8 הראשון הוא יעד והשני X8 הוא מקור
לולאה ב'
לדלג:
כמו ב-6502 µP ו-X64 µP, התווית ב-ARM 64 µP מתחילה בתחילת השורה. שאר ההוראות מתחילות ברווחים מסוימים לאחר תחילת השורה. עם x64 ו-ARM 64, אחרי התווית מופיעים נקודתיים ושורה חדשה. בעוד עם 6502, אחרי התווית מופיעה הוראה אחרי רווח. בקוד הקודם, ההוראה הראשונה שהיא 'CBZ X8, דלג' פירושה שאם הערך ב-X8 הוא אפס, המשך בתווית 'דלג:', דילוג על ההוראות שביניהן והמשך עם שאר ההוראות למטה 'לדלג:'. 'לולאה B' היא קפיצה ללא תנאי לתווית 'לולאה'. ניתן להשתמש בכל שם תווית אחר במקום 'לולאה'.
אז, כמו עם 6502 µP, השתמש בהוראות הסניף כדי ליצור לולאה עם ה-ARM 64.
6.46 ARM 64 קלט/פלט
כל הציוד ההיקפי של ARM (יציאות פנימיות) ממופי זיכרון. המשמעות היא שממשק התכנות הוא קבוצה של אוגרים ממוענים בזיכרון (יציאות פנימיות). הכתובת של אוגר כזה היא היסט מכתובת בסיס זיכרון ספציפית. זה דומה לאופן שבו ה-6502 עושה את הקלט/פלט. ל-ARM אין אפשרות למרחב כתובות I/O נפרד.
6.47 ערימת ARM 64
ל-ARM 64 יש מחסנית בזיכרון (RAM) בצורה דומה שיש ל-6502 ו-x64. עם זאת, עם ARM64, אין קוד דחיפה או פופ. הערימה ב-ARM 64 גם גדלה כלפי מטה. הכתובת במצביע המחסנית מצביעה ממש אחרי הביט האחרון של הערך האחרון שהוצב בערימה.
הסיבה לכך שאין קוד פופ או דחיפה גנרי עבור ARM64 היא ש-ARM 64 מנהל את הערימה שלו בקבוצות של 16 בתים עוקבים. עם זאת, הערכים קיימים בקבוצות בתים של בת אחד, שני בתים, ארבעה בתים ו-8 בתים. אז, ניתן למקם ערך אחד בערימה, ושאר המקומות (מיקומי בתים) כדי לפצות על 16 בתים מרופדים בבתים דמה. יש לזה את החיסרון של בזבוז זיכרון. פתרון טוב יותר הוא למלא את המיקום של 16 בתים בערכים קטנים יותר ולכתוב קוד כלשהו של מתכנת שעוקב אחר מאיפה מגיעים הערכים במיקום של 16 בתים (אוגרים). קוד נוסף זה נחוץ גם למשיכת הערכים לאחור. חלופה לכך היא למלא שני אוגרים של 8 בתים למטרות כלליות בערכים השונים, ולאחר מכן לשלוח את התוכן של שני האוגרים של 8 בתים לערימה. עדיין יש צורך בקוד נוסף כאן כדי לעקוב אחר הערכים הקטנים הספציפיים שנכנסים לערימה ויוצאים מהמחסנית.
הקוד הבא מאחסן ארבעה נתונים של 4 בתים בערימה:
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
ארבעת הבתים הראשונים (w) של אוגרים - x0, x1, x2 ו-x3 - נשלחים למיקומי בתים רצופים בערימה. שימו לב לשימוש ב'str' ולא ב'דחיפה'. שימו לב לסמל הקריאה בסוף כל הוראה. מכיוון שערימת הזיכרון גדלה כלפי מטה, הערך הראשון של ארבעת הבתים מתחיל במיקום שהוא מינוס ארבעה בתים מתחת למיקום מצביע המחסנית הקודם. שאר ערכי ארבעת הבתים עוקבים, יורדים. קטע הקוד הבא יעשה את המקבילה הנכונה (ובסדר) של פתיחת ארבעת הבתים:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
שימו לב לשימוש ב-ldr opcode במקום pop. שימו לב גם שסימן הקריאה אינו בשימוש כאן.
ניתן לשלוח את כל הבתים ב-X0 (8 בתים) וב-X1 (8 בתים) למיקום של 16 בתים בערימה באופן הבא:
stp x0, x1, [sp, #-16]! ; 8 + 8 = 16
במקרה זה, אין צורך ברישום x2 (w2) ו-x3 (w3). כל הבתים המבוקשים נמצאים באוגרי X0 ו-X2. שימו לב ל-stp opcode לאחסון הזוגות של תוכן הרישום ב-RAM. שימו לב גם לסמל הקריאה. המקבילה לפופ היא:
ldp x0, x1, [sp], #0
אין סימן קריאה להוראה זו. שימו לב לקוד ה-Opcode LDP במקום LDR לטעינת שני מיקומי נתונים עוקבים מהזיכרון לשני אוגרי µP. זכור גם שהעתקה מהזיכרון לאגר µP היא בטעינה, לא להתבלבל עם טעינת קובץ מהדיסק ל-RAM, והעתקה מאוגר µP ל-RAM היא אחסון.
6.48 תת שגרה
תת שגרה היא גוש קוד שמבצע משימה, אופציונלית על סמך כמה ארגומנטים ומחזיר תוצאה אופציונלית. לפי המוסכמה, האוגרים R0 עד R3 (ארבעה אוגרים) משמשים להעברת הארגומנטים (פרמטרים) לתת-שגרה, ו-R0 משמש להעברת תוצאה חזרה למתקשר. תת-שגרה שצריכה יותר מ-4 כניסות משתמשת במחסנית עבור הכניסות הנוספות. כדי להתקשר לשגרת משנה, השתמש בקישור או בהוראת הסניף המותנה. התחביר של הוראת הקישור הוא:
תווית BL
כאשר BL הוא ה-opcode והתווית מייצגת את ההתחלה (הכתובת) של תת-השגרה. סניף זה הוא ללא תנאי, קדימה או אחורה בתוך 128MB. התחביר להוראת הסניף המותנה הוא:
תווית B.cond
כאשר cond הוא התנאי, למשל, eq (שווה) או ne (לא שווה). לתוכנית הבאה יש את תת-השגרה doadd שמוסיפה את הערכים של שני ארגומנטים ומחזירה תוצאה ב-R0:
מסלול משנה של AREA, קוד, לקריאה בלבד; תן שם לגוש הקוד הזה
כניסה ; סמן הוראה ראשונה לביצוע
התחל MOV r0, #10; הגדר פרמטרים
MOV r1, #3
BL doadd ; תת שגרת שיחות
עצור MOV r0, #0x18 ; angel_SWIreason_ReportException
LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit
SVC #0x123456 ; ARM semihosting (לשעבר SWI)
doadd ADD r0, r0, r1; קוד תת שגרה
BX lr ; חזרה משגרת המשנה
;
END ; סמן את סוף הקובץ
המספרים שיש להוסיף הם עשרוני 10 ועשרוני 3. שתי השורות הראשונות בבלוק קוד (תוכנית) זה יוסברו בהמשך. שלוש השורות הבאות שולחות 10 ל-R0 register ו-3 ל-R1 register, וגם קוראת ל-doadd sub-routine. ה-'doadd' הוא התווית שמכילה את הכתובת של תחילת תת-השגרה.
תת-השגרה מורכבת משני קווים בלבד. השורה הראשונה מוסיפה את התוכן 3 של R לתוכן 10 של R0 מה שמאפשר את התוצאה של 13 ב-R0. השורה השנייה עם ה-BX opcode ואופרנד LR חוזרת מתת-השגרה לקוד המתקשר.
ימין
קוד ה-RET ב-ARM 64 עדיין עוסק בתת-השגרה, אך פועל באופן שונה מ-RTS ב-6502 או RET ב-x64, או השילוב של 'BX LR' ב-ARM 64. ב-ARM 64, התחביר של RET הוא:
ישר {Xn}
הוראה זו נותנת את ההזדמנות לתוכנית להמשיך עם תת-שגרה שאינה תת-השגרה המתקשרת, או פשוט להמשיך עם הוראה אחרת וקטע הקוד הבא שלה. Xn הוא אוגר למטרות כלליות שמכיל את הכתובת שאליה התוכנית צריכה להמשיך. הוראה זו מסתעפת ללא תנאי. זה כברירת מחדל לתוכן של X30 אם Xn לא ניתן.
נוהל שיחה סטנדרטי
אם המתכנת רוצה שהקוד שלו יקיים אינטראקציה עם קוד שנכתב על ידי מישהו אחר או עם קוד שמיוצר על ידי מהדר, המתכנת צריך להסכים עם האדם או עם כותב המהדר על הכללים לשימוש ברישום. עבור ארכיטקטורת ARM, כללים אלה נקראים Procedure Call Standard או PCS. מדובר בהסכמים בין שניים או שלושה הצדדים. ה-PCS מפרט את הדברים הבאים:
- באילו אוגרי µP משתמשים כדי להעביר את הארגומנטים לפונקציה (תת שגרת)
- באילו אוגרי µP משתמשים כדי להחזיר את התוצאה לפונקציה שמבצעת את ההתקשרות הידועה בשם המתקשר
- איזה µP רושם את הפונקציה שנקראת, הידועה בשם הנקרא, יכולה להשחית
- איזה µP רושם את הנמען לא יכול להשחית
6.49 הפסקות
ישנם שני סוגים של מעגלי בקר פסיקה זמינים עבור מעבד ARM:
- בקר פסיקות סטנדרטי: מטפל הפסיקות קובע איזה התקן דורש שירות על ידי קריאת אוגר מפת סיביות של התקן בבקר הפסיקות.
- בקר פסיקות וקטור (VIC): נותן עדיפות לפסיקות ומפשט את הקביעה של איזה מכשיר גרם להפסקה. לאחר שיוך עדיפות וכתובת מטפל לכל פסיקה, ה-VIC מציג אות פסיקה למעבד רק אם העדיפות של פסיקה חדשה גבוהה יותר מהמטפל בפסיקה המבצע כעת.
הערה : חריג מתייחס לשגיאה. הפרטים עבור בקר הפסיקה הווקטורית עבור מחשב ARM 32 סיביות הם כדלקמן (64 סיביות דומה):
| טבלה 6.49.1 חריג/הפרעה וקטור ARM עבור מחשב 32 סיביות |
|||
|---|---|---|---|
| חריג/הפרעה | יד קצרה | כתובת | כתובת גבוהה |
| אִתחוּל | אִתחוּל | 0x00000000 | 0xffff0000 |
| הוראה לא מוגדרת | UNDEF | 0x00000004 | 0xffff0004 |
| הפרעה בתוכנה | SWI | 0x00000008 | 0xffff0008 |
| אחזור מראש | פאבט | 0x0000000C | 0xffff000C |
| תאריך הפלה | DABT | 0x00000010 | 0xffff0010 |
| שמורות | – | 0x00000014 | 0xffff0014 |
| בקשת הפסקה | IRQ | 0x00000018 | 0xffff0018 |
| בקשת הפסקה מהירה | FIQ | 0x0000001C | 0xffff001C |
זה נראה כמו הסידור לארכיטקטורת 6502 שבו NMI , BR , ו IRQ יכולים להיות מצביעים בעמוד אפס, והרוטינות המתאימות נמצאות גבוה בזיכרון (ROM OS). תיאורים קצרים של השורות בטבלה הקודמת הם כדלקמן:
אִתחוּל
זה קורה כאשר המעבד מופעל. הוא מאתחל את המערכת ומגדיר את הערימות עבור מצבי מעבד שונים. זה החריג בעדיפות הגבוהה ביותר. עם הכניסה למטפל האיפוס, ה-CPSR נמצא במצב SVC וגם סיביות IRQ ו-FIQ מוגדרות ל-1, מה שמסווה כל פסיקה.
תאריך ההפלה
העדיפות השנייה הגבוהה ביותר. זה קורה כאשר אנו מנסים לקרוא/לכתוב לכתובת לא חוקית או לגשת להרשאת גישה שגויה. עם הכניסה ל-Data Abort Handler, ה-IRQs יושבתו (I-bit set 1) ו-FIQ יופעל. ה-IRQs רעולי פנים, אך FIQs נשמרים חשופות.
FIQ
הפסקת העדיפות הגבוהה ביותר, IRQ ו-FIQs, מושבתות עד לטיפול ב-FIQ.
IRQ
ההפרעה בעדיפות גבוהה, המטפל ב-IRQ, מוזנת רק אם אין FIQ מתמשך וביטול נתונים.
Pre-Fetch Abort
זה דומה לביטול נתונים אבל קורה בכשל באחזור כתובת. עם הכניסה למטפל, IRQs מושבתים אך FIQs נשארים מופעלים ויכולים להתרחש במהלך הפסקת אחזור מראש.
SWI
חריג פסיקת תוכנה (SWI) מתרחש כאשר הוראת SWI מבוצעת ואף אחד מהחריגים האחרים בעדיפות גבוהה יותר סומן.
הוראה לא מוגדרת
חריג הפקודה הבלתי מוגדרת מתרחשת כאשר הוראה שאינה בקבוצת הוראות ARM או Thumb מגיעה לשלב הביצוע של הצינור ואף אחד מהחריגים האחרים לא סומן. זו אותה עדיפות כמו SWI כפי שיכולה לקרות בכל פעם. המשמעות היא שהפקודה שמתבצעת לא יכולה להיות גם הוראת SWI וגם הוראה לא מוגדרת בו-זמנית.
טיפול בחריגים ב-ARM
האירועים הבאים מתרחשים כאשר מתרחש חריג:
- אחסן את ה-CPSR ל-SPSR של מצב החריגה.
- המחשב מאוחסן ב-LR של מצב חריג.
- פנקס הקישורים מוגדר לכתובת ספציפית בהתבסס על ההוראה הנוכחית. לדוגמה: עבור ISR, LR = הוראה אחרונה שבוצעה + 8.
- עדכן את ה-CPSR לגבי החריג.
- הגדר את המחשב לכתובת של מטפל החריגים.
6.5 הוראות ונתונים
נתונים מתייחסים למשתנים (תוויות עם הערכים שלהם) ולמערכים ומבנים אחרים הדומים למערך. המחרוזת היא כמו מערך של תווים. מערך של מספרים שלמים נראה באחד מהפרקים הקודמים. ההוראות מתייחסות לקודים ולאופרנדים שלהם. ניתן לכתוב תוכנית עם קודים ונתונים מעורבבים בחלק המשך אחד של הזיכרון. לגישה הזו יש חסרונות אבל לא מומלצת.
יש לכתוב תוכנית עם ההוראות תחילה, ולאחר מכן את הנתונים (ריבוי של נתון הוא נתונים). ההפרדה בין ההוראות לנתונים יכולה להיות רק כמה בתים. עבור תוכנית, גם ההוראות וגם הנתונים יכולים להיות בחלק אחד או שניים נפרדים בזיכרון.
6.6 אדריכלות הרווארד
אחד המחשבים המוקדמים נקרא הרווארד מארק הראשון (1944). ארכיטקטורת הרווארד קפדנית משתמשת במרחב כתובות אחד להוראות תוכנית ובמרחב כתובות נפרד אחר לנתונים. זה אומר שיש שני זיכרונות נפרדים. הבא מציג את הארכיטקטורה:
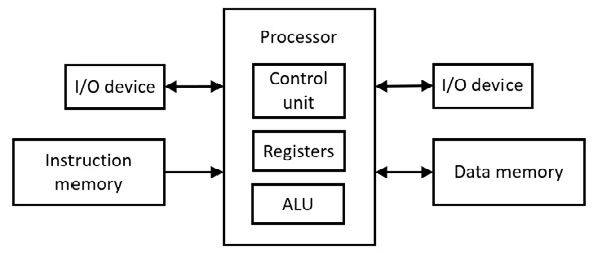
איור 6.71 אדריכלות הרווארד
יחידת הבקרה עושה את פענוח ההוראות. יחידת הלוגיקה האריתמטית (ALU) עושה את פעולות החשבון עם לוגיקה קומבינציה (שערים). ALU גם עושה את הפעולות הלוגיות (למשל הסטות).
עם המיקרו-מעבד 6502, הוראה עוברת למיקרו-מעבד תחילה (יחידת בקרה) לפני שהנתון (יחיד לנתונים) עובר לאוגר µP לפני שהם יוצרים אינטראקציה. זה צריך לפחות שני פולסים של שעון וזה לא גישה בו-זמנית להוראה ולנתון. מצד שני, ארכיטקטורת הרווארד מספקת גישה בו-זמנית להוראות ולנתונים, כאשר גם הוראות וגם דאטום נכנסים ל-µP בו-זמנית (אופקוד ליחידת בקרה ודאטום ל-µP אוגר), חוסכת לפחות פולס שעון אחד. זוהי צורה של מקביליות. צורה זו של מקביליות משמשת במטמון החומרה בלוחות אם מודרניים (עיין בדיון הבא).
6.7 זיכרון מטמון
זיכרון מטמון (RAM) הוא אזור זיכרון מהיר (בהשוואה למהירות הזיכרון הראשי) המאחסן באופן זמני את הוראות התוכנית או הנתונים לשימוש עתידי. זיכרון המטמון פועל מהר יותר מהזיכרון הראשי. בדרך כלל, הוראות או פריטי נתונים אלה מאוחזרים מהזיכרון הראשי האחרון וסביר להניח שיזדקקו שוב בקרוב. המטרה העיקרית של זיכרון המטמון היא להגביר את מהירות הגישה החוזרת לאותם מיקומי זיכרון ראשיים. כדי להיות יעילה, הגישה לפריטים המאוחסנים במטמון חייבת להיות מהירה משמעותית מגישה למקור המקורי של ההוראות או הנתונים, המכונה חנות הגיבוי.
כאשר נעשה שימוש במטמון, כל ניסיון לגשת למיקום זיכרון ראשי מתחיל בחיפוש במטמון. אם הפריט המבוקש קיים, המעבד מאחזר ומשתמש בו באופן מיידי. זה נקרא Cache Hit. אם חיפוש המטמון נכשל (החמצת מטמון), יש לאחזר את ההוראה או פריט הנתונים מחנות הגיבוי (הזיכרון הראשי). בתהליך של אחזור הפריט המבוקש, עותק מתווסף למטמון לשימוש צפוי בעתיד הקרוב.
יחידת ניהול זיכרון
יחידת ניהול הזיכרון (MMU) היא מעגל המנהל את הזיכרון הראשי ורישומי הזיכרון הקשורים בלוח האם. בעבר, זה היה מעגל משולב נפרד בלוח האם; אבל היום, זה בדרך כלל חלק מהמיקרו-מעבד. ה-MMU אמור לנהל גם את המטמון (המעגל) שהוא גם חלק מהמיקרו-מעבד כיום. מעגל המטמון הוא מעגל משולב נפרד בעבר.
זיכרון RAM סטטי
לזיכרון RAM סטטי (SRAM) יש זמן גישה מהיר משמעותית מ-DRAM, אם כי על חשבון מעגלים מורכבים משמעותית. תאי סיביות SRAM תופסים הרבה יותר מקום על קוביית המעגל המשולבת מאשר התאים של התקן DRAM שמסוגל לאחסן כמות שווה של נתונים. הזיכרון הראשי (RAM) מורכב בדרך כלל מ-DRAM (RAM דינמי).
זיכרון המטמון משפר את ביצועי המחשב מכיוון שאלגוריתמים רבים המבוצעים על ידי מערכות הפעלה ויישומים מציגים את מקום ההפניה. אזור ההתייחסות מתייחס לשימוש חוזר בנתונים שניגשו אליהם לאחרונה. זה מכונה יישוב זמני. בלוח אם מודרני, זיכרון המטמון נמצא באותו מעגל משולב כמו המיקרו-מעבד. הזיכרון הראשי (DRAM) רחוק ונגיש דרך האוטובוסים. יישוב ההתייחסות מתייחס גם ליישוב מרחבי. היישוב המרחבי קשור למהירות הגבוהה יותר של גישה לנתונים בגלל הקרבה הפיזית.
ככלל, אזורי זיכרון המטמון קטנים (במספר מיקומי בתים) בהשוואה למאגר הגיבוי (זיכרון ראשי). התקני זיכרון המטמון מתוכננים למהירות מרבית, מה שאומר בדרך כלל שהם מורכבים ויקרים יותר לביט מאשר טכנולוגיית אחסון הנתונים המשמשת בחנות הגיבוי. בשל גודלם המוגבל, התקני זיכרון המטמון נוטים להתמלא במהירות. כאשר למטמון אין מיקום זמין לאחסון רשומה חדשה, יש למחוק ערך ישן יותר. בקר המטמון משתמש במדיניות החלפת מטמון כדי לבחור איזה ערך מטמון ידרוס על ידי הערך החדש.
המטרה של זיכרון המטמון של המיקרו-מעבד היא למקסם את אחוז כניסות המטמון לאורך זמן, ובכך לספק את הקצב הממושך הגבוה ביותר של ביצוע פקודות. כדי להשיג מטרה זו, הלוגיקה של שמירה במטמון חייבת לקבוע אילו הוראות ונתונים יוכנסו למטמון ויישמרו לשימוש עתידי קרוב.
ללוגיקת האחסון במטמון של מעבד אין ביטחון שפריט נתונים שמור ייעשה אי פעם שימוש שוב לאחר שהוא יוכנס למטמון.
ההיגיון של שמירה במטמון מסתמך על הסבירות שבגלל מקומיות זמנית (חוזרת על פני זמן) ומרחבית (מרחב), יש סיכוי טוב מאוד שהגישה לנתונים המאוחסנים במטמון תהיה בעתיד הקרוב. ביישומים מעשיים במעבדים מודרניים, כניסות מטמון מתרחשות בדרך כלל ב-95 עד 97 אחוז מהגישה לזיכרון. מכיוון שהשהייה של זיכרון המטמון היא חלק קטן מהשהייה של DRAM, קצב פגיעה גבוה במטמון מוביל לשיפור ביצועים מהותי בהשוואה לתכנון נטול מטמון.
קצת מקביליות עם מטמון
כאמור, לתוכנית טובה בזיכרון יש את ההוראות מופרדות מהנתונים. בחלק ממערכות המטמון, קיים מעגל מטמון ב'שמאל' של המעבד ויש מעגל מטמון נוסף ב'ימין' של המעבד. המטמון השמאלי מטפל בהוראות של תוכנית (או אפליקציה) והמטמון הימני מטפל בנתונים של אותה תוכנית (או אותה אפליקציה). זה מוביל למהירות מוגברת טובה יותר.
6.8 תהליכים וחוטים
גם למחשבי CISC וגם למחשבי RISC יש תהליכים. תהליך הוא על התוכנה. תוכנית שפועלת (מבצעת) היא תהליך. מערכת ההפעלה מגיעה עם תוכניות משלה. בזמן שהמחשב פועל, פועלות גם התוכניות של מערכת ההפעלה המאפשרות למחשב לעבוד. אלו תהליכים של מערכת הפעלה. המשתמש או המתכנת יכול לכתוב תוכניות משלו. כאשר התוכנית של המשתמש פועלת, זהו תהליך. זה לא משנה אם התוכנית כתובה בשפת assembly או בשפה ברמה גבוהה כמו C או C++. כל התהליכים (משתמש או מערכת הפעלה) מנוהלים על ידי תהליך אחר הנקרא 'לוח זמנים'.
חוט הוא כמו תת-תהליך השייך לתהליך. תהליך יכול להתחיל ולהתפצל לשרשורים ואז עדיין ממשיך כתהליך אחד. תהליך ללא חוטים יכול להיחשב כחוט הראשי. תהליכים והשרשורים שלהם מנוהלים על ידי אותו מתזמן. המתזמן עצמו הוא תוכנית כאשר הוא תושב בדיסק מערכת ההפעלה. כאשר פועל בזיכרון, המתזמן הוא תהליך.
6.9 ריבוי עיבודים
חוטים מנוהלים כמעט כמו תהליכים. ריבוי עיבוד פירושו הפעלת יותר מתהליך אחד בו זמנית. ישנם מחשבים עם מעבד אחד בלבד. ישנם מחשבים עם יותר ממעבד אחד. עם מיקרו-מעבד יחיד, התהליכים ו/או החוטים משתמשים באותו מעבד בצורה של שזירה (או חיתוך זמן). זה אומר שתהליך משתמש במעבד ועוצר בלי לסיים. תהליך אחר או חוט משתמש במעבד ועוצר מבלי לסיים. לאחר מכן, תהליך אחר או חוט משתמש במיקרו-מעבד ועוצר מבלי לסיים. זה נמשך עד שכל התהליכים והשרשורים שהיו בתור על ידי המתזמן קיבלו חלק מהמעבד. זה מכונה ריבוי עיבוד במקביל.
כאשר יש יותר ממעבד אחד, קיים ריבוי עיבוד מקביל, בניגוד למקביל. במקרה זה, כל מעבד מריץ תהליך או שרשור מסוים, שונה ממה שמפעיל המעבד השני. כל המעבדים באותו לוח אם מריצים את התהליכים השונים שלהם ו/או חוטים שונים בו-זמנית בריבוי עיבוד מקביל. התהליכים והשרשורים בריבוי עיבוד מקביל עדיין מנוהלים על ידי המתזמן. ריבוי עיבוד מקביל מהיר יותר מאשר ריבוי עיבוד במקביל.
בשלב זה, הקורא עשוי לתהות עד כמה עיבוד מקביל מהיר יותר מעיבוד מקביל. הסיבה לכך היא שהמעבדים חולקים (צריכים להשתמש בזמנים שונים) את אותם זיכרון ויציאות קלט/פלט. ובכן, עם השימוש במטמון, הפעולה הכוללת של לוח האם מהירה יותר.
6.10 דפדוף
יחידת ניהול הזיכרון (MMU) היא מעגל שנמצא קרוב למיקרו-מעבד או בשבב המיקרו-מעבד. הוא מטפל במפת הזיכרון או בהחלפה ובבעיות זיכרון אחרות. לא למחשב 6502 µP ולא למחשב Commodore-64 יש MMU כשלעצמו (אם כי עדיין יש ניהול זיכרון ב-Commodore-64). ה-Commodore-64 מטפל בזיכרון על ידי דפדוף כאשר כל עמוד הוא 256 10 אורך בתים (100 16 באורך בתים). לא הייתה חובה עליו לטפל בזיכרון באמצעות דפדוף. זה עדיין יכול להיות רק מפת זיכרון ואז תוכניות שפשוט מתאימות את עצמן לאזורים הייעודיים השונים שלהן. ובכן, ההחלפה היא אחת הדרכים לספק שימוש יעיל בזיכרון מבלי שיהיו חלקי זיכרון רבים שאינם יכולים להכיל נתונים או תוכנית.
ארכיטקטורת המחשב x86 386 שוחררה בשנת 1985. אפיק הכתובות הוא ברוחב 32 סיביות. אז בסך הכל 2 32 = 4,294,967,296 מרחב כתובות אפשרי. מרחב הכתובות הזה מחולק ל-1,048,576 עמודים = 1,024 KB דפים. עם מספר עמודים זה, עמוד אחד מורכב מ-4,096 בתים = 4 KB. הטבלה הבאה מציגה את דפי הכתובות הפיזיים עבור ארכיטקטורת x86 32 סיביות:
| טבלה 6.10.1 דפים ניתנים להתייחסות פיזית עבור ארכיטקטורת x86 |
||
|---|---|---|
| בסיס 16 כתובות | דפים | בסיס 10 כתובות |
| FFFFF000 – FFFFFFFF | עמוד 1,048,575 | 4,294,963,200 - 4,294,967,295 |
| FFFFE000 – FFFFEFFF | עמוד 1,044,479 | 4,294,959,104 - 4,294,963,199 |
| FFFFD000 – FFFFDFFF | עמוד 1,040,383 | 4,294,955,008 - 4,294,959,103 |
| | | | |
| | | |
| | | |
| 00002000 - 00002FFF | עמוד 2 | 8,192 – 12,288 |
| 00001000 – 00001FFF | עמוד 1 | 4,096 – 8,191 |
| 00000000 - 00000FFF | עמוד 0 | 0 – 4,095 |
אפליקציה כיום מורכבת מיותר מתוכנית אחת. תוכנית אחת יכולה לקחת פחות מעמוד (פחות מ-4096) או שהיא יכולה לקחת שני עמודים או יותר. אז, יישום יכול לקחת עמוד אחד או יותר כאשר כל עמוד באורך 4096 בתים. אנשים שונים יכולים לכתוב בקשה, כאשר כל אדם מוקצה לעמוד אחד או יותר.
שימו לב שעמוד 0 הוא מ-00000000H ל-00000FFF
עמוד 1 הוא מ-00001000H ל-00001FFFH, עמוד 2 הוא מ-00002000 ח – 00002FFF ח , וכולי. עבור מחשב 32 סיביות, ישנם שני אוגרים של 32 סיביות במעבד עבור כתובת עמוד פיזי: האחד עבור כתובת הבסיס והשני עבור כתובת האינדקס. כדי לגשת למיקומי הבתים של עמוד 2, למשל, הרשום עבור כתובת הבסיס צריך להיות 00002 ח שהם 20 הסיביות הראשונות (משמאל) עבור כתובות ההתחלה של עמוד 2. שאר הביטים בטווח של 000 ח ל-FFF ח נמצאים בפנקס הנקרא 'אוגר אינדקס'. אז, ניתן לגשת לכל הבתים בדף על ידי הגדלת התוכן ברישום האינדקס מ-000 ח ל-FFF ח . התוכן בפנקס האינדקס מתווסף לתוכן שאינו משתנה במאגר הבסיס כדי לקבל את הכתובת האפקטיבית. סכמת הפנייה לאינדקס נכונה עבור שאר הדפים.
עם זאת, לא ממש כך נכתבת תוכנית שפת ההרכבה לכל עמוד. עבור כל עמוד, המתכנת כותב את הקוד החל מעמוד 000 ח לעמוד FFF ח . מכיוון שהקוד בדפים שונים מחוברים, המהדר משתמש בכתובת האינדקס כדי לחבר את כל הכתובות הקשורות בדפים שונים. לדוגמה, בהנחה שעמוד 0, עמוד 1 ועמוד 2 מיועדים ליישום אחד ולכל אחד יש את ה-555 ח כתובת שמחוברת זו לזו, המהדר מבצע קומפילציה באופן שכאשר 555 ח של עמוד 0 יש לגשת, 00000 ח יהיה במאגר הבסיס ו-555 ח יהיה בפנקס האינדקסים. מתי 555 ח של עמוד 1 יש לגשת, 00001 ח יהיה במאגר הבסיס ו-555 ח יהיה בפנקס האינדקסים. מתי 555 ח של עמוד 2 יש לגשת, 00002 ח יהיה בפנקס הבסיס ו-555H יהיה בפנקס האינדקסים. זה אפשרי מכיוון שניתן לזהות את הכתובות באמצעות תוויות (משתנים). המתכנתים השונים צריכים להסכים על שם התוויות שישמשו עבור הכתובות המתחברות השונות.
זיכרון וירטואלי של עמוד
ניתן לשנות את ההחלפה, כפי שתואר קודם לכן, כדי להגדיל את גודל הזיכרון בטכניקה המכונה 'זיכרון עמוד וירטואלי'. בהנחה שלכל דפי הזיכרון הפיזיים, כפי שתואר קודם, יש משהו (הוראות ונתונים), לא כל הדפים פעילים כרגע. הדפים שאינם פעילים כעת נשלחים לדיסק הקשיח ומוחלפים בדפים מהדיסק הקשיח שצריכים לפעול. בדרך זו, גודל הזיכרון גדל. ככל שהמחשב ממשיך לפעול, הדפים שלא פעילים מוחלפים בדפים בדיסק הקשיח שעשויים להיות עדיין הדפים שנשלחו מהזיכרון לדיסק. כל זה נעשה על ידי יחידת ניהול הזיכרון (MMU).
6.11 בעיות
מומלץ לקורא לפתור את כל הבעיות בפרק לפני המעבר לפרק הבא.
1) תן את הדמיון וההבדלים של ארכיטקטורות המחשב CISC ו-RISC. ציין דוגמה אחת של כל אחד ממחשבי SISC ו-RISC.
2) א) מהם השמות הבאים למחשב CISC במונחים של ביטים: בייט, מילה, מילה כפולה, מרובעת ומילה כפולה.
ב) מהם השמות הבאים למחשב RISC מבחינת סיביות: בייט, חצי מילה, מילה ומילה כפולה.
ג) כן או לא. האם doubleword ו-quadword משמעותם אותם דברים גם בארכיטקטורות CISC וגם RISC?
3 א) עבור x64, מספר הבתים עבור הוראות שפת ההרכבה נע בין מה למה?
ב) האם מספר הבתים עבור כל הוראות שפת ההרכבה עבור ARM 64 קבוע? אם כן, מהו מספר הבתים עבור כל ההוראות?
4) רשום את הוראות שפת ההרכבה הנפוצות ביותר עבור x64 והמשמעויות שלהן.
5) רשום את הוראות שפת ההרכבה הנפוצות ביותר עבור ARM 64 והמשמעויות שלהן.
6) צייר תרשים בלוקים מסומן של אדריכלות המחשב הישן של הרווארד. הסבר כיצד נעשה שימוש בהוראות ותכונות הנתונים שלו במטמון של מחשבים מודרניים.
7) להבדיל בין תהליך לחוט ולתת את שם התהליך המטפל בתהליכים ובשרשורים ברוב מערכות המחשוב.
8) הסבירו בקצרה מהו ריבוי עיבודים.
9) א) הסבירו את ההחלפה כפי שישים לארכיטקטורת המחשב x86 386 µP.
ב) כיצד ניתן לשנות את ההחלפה כדי להגדיל את גודל הזיכרון כולו?