'ב'פנדות', נוכל לקרוא בקלות את קובץ הטקסט בעזרת שיטת 'פנדות'. 'Pandas' מספק לנו את ההזדמנות לקרוא את קובץ הטקסט. 'Pandas' נותן שיטות מובנות שונות לקריאת קובץ הטקסט. נדון בכל השיטות במדריך זה יחד עם כל הפרמטרים כאן ונסביר אותם בפירוט. כמו כן, אנו נקרא את קובץ הטקסט ב'פנדות' על ידי שימוש בשיטות של 'פנדות' בקודים שלנו כאן.'
שיטות לקריאת קובץ הטקסט ב'פנדות'
ב'פנדות', יש לנו שלוש שיטות שעוזרות לנו בקריאת קובץ הטקסט. עשינו כאן גם כמה דוגמאות שבהן קראנו את קובץ הטקסט. השיטות שה'פנדות' מספקות נדונות להלן:
-
- על ידי שימוש בשיטת pd.read_csv().
- על ידי שימוש בשיטת pd.read_table().
- על ידי שימוש בשיטת pd.read_fwf().
כעת, אנו מסבירים את התחביר של כל השיטות הללו וגם דנים בפרמטרים של כל השיטות בפירוט במדריך זה.
תחביר של read_csv()
pd.read_csv ( 'filename.txt', ספטמבר =' ', כּוֹתֶרֶת =אין, שמות = [ 'Col_name1', 'Col_name2, 'Col_name2', ………….. ] )
בשיטה זו נוסיף תחילה את שם קובץ הטקסט שאת הנתונים שלו אנו רוצים לקרוא, והוא הפרמטר הראשון של שיטה זו. לאחר מכן, אנו מניחים את ה'ספ', שהוא מפריד בשיטה זו, ומציבים כאן את החלל בתור הדמות כך שהוא יחשב את החלל כמפריד. לאחר מכן, יש לנו את פרמטר ה-header, והערך 'None' של פרמטר זה משמש, כך שהוא יצור את כותרת ברירת המחדל, ואם לא נוסיף את הפרמטר הזה, הוא ישקול את השורה הראשונה של קובץ הטקסט בתור הכותרת. בפרמטר 'שמות', נוכל להוסיף את שמות העמודות שעלינו להוסיף ככותרת.
תחביר של read_table()
pd.read_table ( 'filename.txt' , תוחם = '' )
בשיטה זו, שמנו את שם הקובץ של קובץ הטקסט כפרמטר הראשון. במפריד, כאשר נציב ' ', הוא ייקח את תו הרווח כמפריד.
תחביר של read_fwf()
pd.read_fwf ( 'filename.txt' )
שיטה זו לוקחת רק פרמטר אחד, שהוא השם של קובץ הטקסט.
כעת, נשתמש בשיטות אלו לקריאת קבצי הטקסט בקודי 'פנדות' והצגת נתוני קובץ הטקסט בטרמינל.
דוגמה מס' 01
אפליקציית 'Spyder' נמצאת כאן בה עשינו את כל הקודים האלה שמוצגים במדריך זה. קובץ הטקסט שאת הנתונים שלו אנו רוצים לקרוא מוצג להלן. אנו נשתמש בשיטת 'read_csv()' לקריאת קובץ טקסט זה ב-'pandas'.
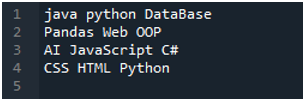
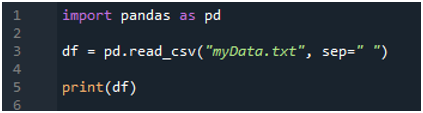
אנו מייבאים תחילה את ספריית 'פנדות' מכיוון שאנו רוצים להשתמש בשיטת 'read_csv()', וזו השיטה של 'פנדות'. אנו ניגשים לשיטה זו רק כאשר ייבאנו את ספריית ה'פנדות'. כאן, אנו מזכירים את 'פנדות כ-pd', ולכן 'pd' זה ממוקם עם שם השיטה לשימוש בו. לאחר מכן, אנו יוצרים כאן משתנה 'df', המשמש לאחסון הנתונים של קובץ הטקסט לאחר הקריאה. אנו מניחים כאן את שיטת 'pd.read_csv()', שעוזרת בקריאת קובץ הטקסט והמרת נתוני קובץ הטקסט ל-DataFrame ואחסונם במשתנה 'df'.
העברנו את שם הקובץ, שהוא 'myData.txt', לכאן, ולאחר מכן אנו משתמשים ב-'sep' ומקצים את התו הריק ל-'sep' הזה. אז התו הריק הזה עובד כמפריד בקובץ הטקסט. לאחר מכן, השתמשנו ב-'print()' למטה, המשמש להדפסת הנתונים של קובץ הטקסט. זה יציג את הנתונים של קובץ הטקסט בטופס DataFrame.
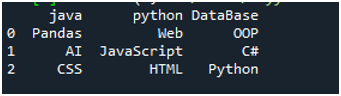
לצורך ביצוע הקוד הזה, עלינו ללחוץ על 'Shift+Enter', והפלט יוצג בטרמינל 'Spyder'. התוצאה של הקוד לעיל מוצגת בצילום המסך הנתון, ותוכלו לראות שהנתונים של קובץ הטקסט מוצגים כ-DataFrame, והשורה הראשונה של קובץ הטקסט שלנו מוצגת כאן בתור שמות העמודות של אותה DataFrame. זה גם מפריד בין הנתונים שבהם תו הרווח נמצא בקובץ הטקסט.
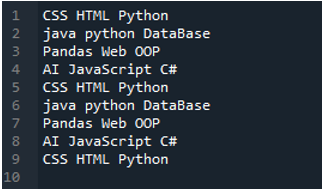
דוגמה מס' 02
קובץ הטקסט שנקרא בדוגמה זו מוצג כאן, ושוב נשתמש בשיטת 'read_csv()' אך עם פרמטרים שונים.
נעשה שימוש בשיטת 'pandas' 'pd.read_csv()', ואנו מעבירים כאן שלושה פרמטרים. ראשית, אנו מציבים את שם הקובץ, שהוא 'Record.txt'. הפרמטר השני הוא הפרמטר 'sep' ומקצה לו את התו הריק, ואז יש לנו את הפרמטר השלישי בו אנו מגדירים את ה-'header' ומכוונים אותו ל-'None', כך שהוא יצור את כותרת ברירת המחדל של ה-DataFrame כאשר אנו מבצעים את הקוד הזה. שמרנו את כל זה במשתנה 'My_Record' וגם הוספנו את 'My_Record' בפונקציה 'print()' להדפסה.

כל הנתונים נשמרים ב-DataFrame, והוא מפריד בין הנתונים שבהם תו הרווח קיים בנתוני קובץ הטקסט. כמו כן, הוא יצר את כותרת ברירת המחדל של ה-DataFrame כאן מכיוון שהתאמנו את הפרמטר 'header' ל-'None'.
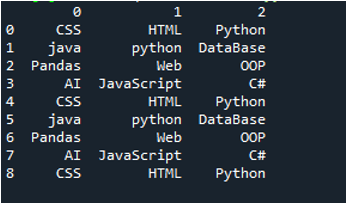
דוגמה מס' 03
קובץ הטקסט של הדוגמה הזו מוצג, ואנחנו נשתמש שוב בשיטת 'read_csv()' עם פרמטרים שהשתנו.
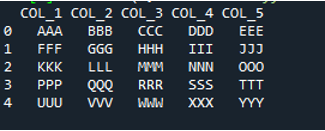
בקוד זה, ארבעה פרמטרים מועברים כאן לשיטת 'pandas' 'pd.read_csv()'. שם קובץ הטקסט הוא הפרמטר הראשון. לפרמטר 'sep' ניתן התו הריק בפרמטר השני. הפרמטר 'header' מוגדר ל-'None' בארגומנט השלישי, וכפרמטר הרביעי, הגדרנו את ה-'names' שיופיעו כשמות העמודות של DataFrame לאחר קריאת קובץ הטקסט, ושמות העמודות הללו הם 'COL_1, COL_2, COL_3, COL_4 ו-COL_5'. כל המידע הזה נשמר במשתנה 'My_Record', ו-'My_Record' נוסף גם לשיטת 'print()' כך שהוא יודפס בטרמינל.

כל המידע של קובץ הטקסט מוצג כאן כ-DataFrame, והוא גם מפריד בין הנתונים שבהם הרווחים מתווספים בקובץ הטקסט. זה גם מוסיף את שמות העמודות בהתאם, שהוספנו למעלה בקוד.
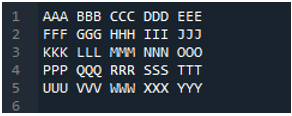
דוגמה מס' 04
זהו קובץ הטקסט שנקרא בדוגמה זו על ידי שימוש בשיטה אחרת, שיטת 'pd.read_table()'.
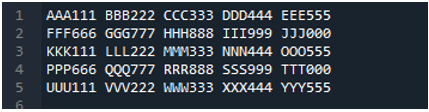
השיטה 'pd.read_table()' מתווספת כאן לקריאת קובץ הטקסט, ואנו מוסיפים 'ABC.txt', שהוא שם קובץ הטקסט. שיטה זו עוזרת בקריאת קובץ הטקסט, כמו כן, התאמנו את הפרמטר 'מפריד' לתו הרווח, כך שהוא יעבוד גם כמו המפריד שהסברנו למעלה. אז כל נתוני הקובץ של הטקסט נשמרים במשתנה 'My_Data' וגם מודפסים כאן.

השורה הראשונית של קובץ הטקסט שלנו מוצגת כאן בתור שמות העמודות של ה-DataFrame, והנתונים של קובץ הטקסט מודפסים כ-DataFrame. בנוסף, הוא מפריד בין הנתונים של קובץ הטקסט שבו תו הרווח נמצא בו.
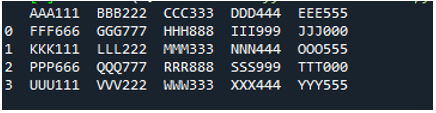
דוגמה מס' 05
כעת, קובץ הטקסט מכיל את הנתונים, המוצגים למטה. אנו נחיל את ה-'read_fwf()' הפעם ונראה כיצד הוא מעבד נתונים לאחר קריאת קובץ הטקסט.
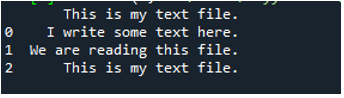
כפי שאנו יודעים ששיטת 'read_fwf()' זו לוקחת רק פרמטר אחד, שהוא שם הקובץ שאנו רוצים לקרוא. אנו מוסיפים כאן 'textfile.txt', שהוא השם של קובץ הטקסט שלנו ומקצים את שיטת הפנדות הזו למשתנה 'File_Data', אשר יאחסן את הנתונים של קובץ הטקסט הזה. לאחר מכן שמנו 'print(File_Data)' כך שהוא גם מדפיס את הנתונים האלה.

כאן, כל הנתונים של קובץ הטקסט מוצגים. זה לא הפריד בין הנתונים שבהם קיימים תווי רווח מכיוון שאין פרמטר כמו 'ספטמבר' או 'מפריד' בפונקציה הזו.
סיכום
מדריך זה מסביר כיצד לקרוא את קובץ הטקסט ב'פנדות' ואילו שיטות משמשות לקריאת קובץ הטקסט ב'פנדות'. דנו בכל השיטות שעוזרות לנו בקריאת קובץ הטקסט ב'פנדות'. חקרנו שלוש שיטות שונות של 'פנדות' לקריאת קבצי הטקסט שלנו ב'פנדות' במדריך זה. הסברנו כאן בפירוט את התחביר של כל השיטות כמו גם את הפרמטרים של כל השיטות וקראנו קבצי טקסט רבים על ידי יישום שיטות שונות עם כל הפרמטרים האפשריים במדריך זה.