מתאר מהיר
פוסט זה ידגים:
כיצד ליישם את ההיגיון של ReAct עם חנות מסמכים ב-LangChain
כיצד ליישם את ההיגיון של ReAct עם חנות מסמכים ב-LangChain?
דגמי השפה מאומנים על מאגר עצום של נתונים הכתובים בשפות טבעיות כמו אנגלית וכו'. הנתונים מנוהלים ומאוחסנים במאגרי המסמכים והמשתמש יכול פשוט לטעון את הנתונים מהחנות ולהכשיר את המודל. אימון המודל יכול לקחת מספר איטרציות שכן כל איטרציה הופכת את המודל ליעיל ומשופר יותר.
כדי ללמוד את תהליך הטמעת לוגיקה של ReAct לעבודה עם חנות המסמכים ב-LangChain, פשוט עקוב אחר המדריך הפשוט הזה:
שלב 1: התקנת מסגרות
ראשית, התחל עם תהליך הטמעת הלוגיקה של ReAct לעבודה עם חנות המסמכים על ידי התקנת המסגרת של LangChain. התקנת המסגרת של LangChain תקבל את כל התלות הנדרשת כדי לקבל או לייבא את הספריות להשלמת התהליך:
pip להתקין langchain
התקן את התלות בוויקיפדיה עבור מדריך זה מכיוון שניתן להשתמש בו כדי לגרום למאגרי המסמכים לעבוד עם הלוגיקה של ReAct:
התקנת pip בויקיפדיה 
התקן את מודולי OpenAI באמצעות פקודת pip כדי לקבל את הספריות שלה ולבנות מודלים של שפה גדולה או LLMs:
pip להתקין openai 
שלב 2: אספקת מפתח API של OpenAI
לאחר התקנת כל המודולים הנדרשים, פשוט להקים את הסביבה באמצעות מפתח ה-API מחשבון OpenAI באמצעות הקוד הבא:
יְבוּא אתהיְבוּא getpass
אתה . בְּעֵרֶך [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'מפתח API של OpenAI:' )
שלב 3: ייבוא ספריות
לאחר הגדרת הסביבה, ייבא מה-LangChain את הספריות הנדרשות כדי להגדיר את הלוגיקה של ReAct לעבודה עם מאגרי המסמכים. שימוש בסוכני LangChain כדי לקבל את DocstoreExplaorer וסוכנים עם סוגיו כדי להגדיר את מודל השפה:
מ langchain. llms יְבוּא OpenAIמ langchain. דוקטורט יְבוּא ויקיפדיה
מ langchain. סוכנים יְבוּא initialize_agent , כְּלִי
מ langchain. סוכנים יְבוּא AgentType
מ langchain. סוכנים . לְהָגִיב . בסיס יְבוּא DocstoreExplorer
שלב 4: שימוש בוויקיפדיה סייר
הגדר את ' דוקטורט ” משתנה עם השיטה DocstoreExplorer() וקוראים לשיטת Wikipedia() בארגומנט שלו. בנה את מודל השפה הגדולה בשיטת OpenAI עם ' text-davinci-002 ' מודל לאחר הגדרת הכלים עבור הסוכן:
דוקטורט = DocstoreExplorer ( ויקיפדיה ( ) )כלים = [
כְּלִי (
שֵׁם = 'לחפש' ,
func = דוקסטור. לחפש ,
תיאור = 'הוא משמש לשאילתות/הנחיות עם החיפוש' ,
) ,
כְּלִי (
שֵׁם = 'הבט מעלה' ,
func = דוקסטור. הבט מעלה ,
תיאור = 'הוא משמש לשאילתות/הנחיות עם חיפוש' ,
) ,
]
llm = OpenAI ( טֶמפֶּרָטוּרָה = 0 , שם המודל = 'text-davinci-002' )
#הגדרת המשתנה על ידי הגדרת המודל עם הסוכן
לְהָגִיב = initialize_agent ( כלים , llm , סוֹכֵן = AgentType. REACT_DOCSTORE , מִלוּלִי = נָכוֹן )
שלב 5: בדיקת המודל
לאחר שהמודל נבנה ומוגדר, הגדר את מחרוזת השאלה והפעל את השיטה עם משתנה השאלה בארגומנט שלו:
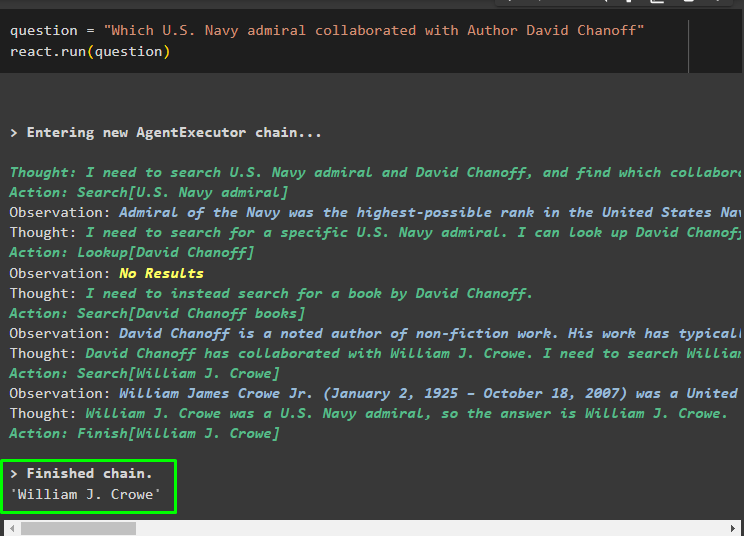
שְׁאֵלָה = 'אשר אדמירל הצי האמריקני שיתף פעולה עם הסופר דיוויד צ'נוף'לְהָגִיב. לָרוּץ ( שְׁאֵלָה )
לאחר ביצוע משתנה השאלה, המודל הבין את השאלה ללא כל תבנית הנחיה חיצונית או הדרכה. המודל עובר הכשרה אוטומטית באמצעות המודל שהועלה בשלב הקודם ויוצר טקסט בהתאם. ההיגיון של ReAct עובד עם מאגרי המסמכים כדי לחלץ מידע על סמך השאלה:
שאל שאלה נוספת מהנתונים שסופקו לדגם מחנויות המסמכים והדגם יחלץ את התשובה מהחנות:
שְׁאֵלָה = 'הסופר דיוויד צ'אנף שיתף פעולה עם וויליאם ג'יי קרואו שכיהן תחת איזה נשיא?'לְהָגִיב. לָרוּץ ( שְׁאֵלָה )
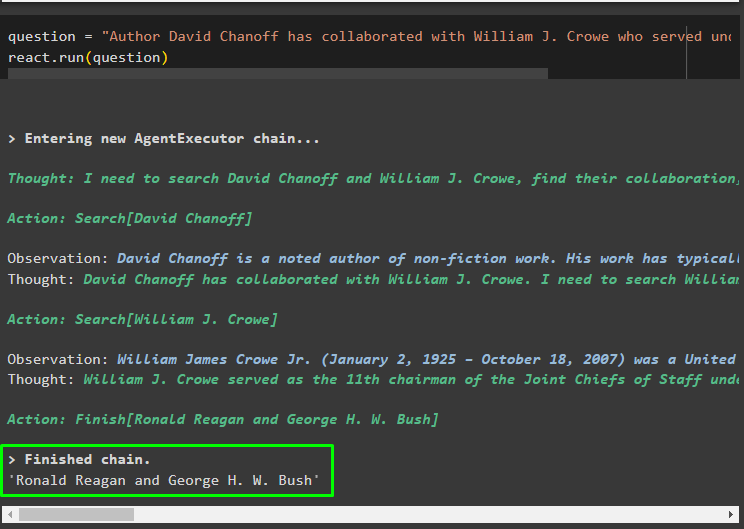
זה הכל על יישום הלוגיקה של ReAct לעבודה עם חנות המסמכים ב-LangChain.
סיכום
כדי ליישם את הלוגיקה של ReAct לעבודה עם חנות המסמכים ב-LangChain, התקן את המודולים או המסגרות לבניית מודל השפה. לאחר מכן, הגדר את הסביבה עבור OpenAI כדי להגדיר את ה-LLM וטען את המודל מחנות המסמכים כדי ליישם את הלוגיקה של ReAct. מדריך זה הרחיב את יישום ההיגיון של ReAct לעבודה עם מאגר המסמכים.