דוגמה 1: קבל את מיקום התבנית מהמחרוזת באמצעות הפונקציה Grep() ב-R
כדי לחלץ את המיקום של התבנית שצוינה מהמחרוזת, הפונקציה grep() של R מופעלת.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)כאן, אנו משתמשים בפונקציה grep() שבה תבנית ה-'+i' מצוינת כארגומנט שיש להתאים בווקטור של מחרוזות. אנו מגדירים את וקטורי התווים המכילים ארבע מחרוזות. לאחר מכן, אנו מגדירים את הארגומנט 'perl' עם הערך TRUE המציין ש-R משתמש בספריית ביטויים רגולריים תואמת perl, והפרמטר 'value' מצוין עם הערך 'FALSE' המשמש לאחזור המדדים של האלמנטים בוקטור התואם את התבנית.
מיקום הדפוס '+i' מכל מחרוזת של תווים וקטוריים מוצג בפלט הבא:

דוגמה 2: התאם את התבנית באמצעות הפונקציה Gregexpr() ב-R
לאחר מכן, אנו מאחזרים את מיקום האינדקס יחד עם אורך המחרוזת המסוימת ב-R באמצעות הפונקציה gregexpr() .
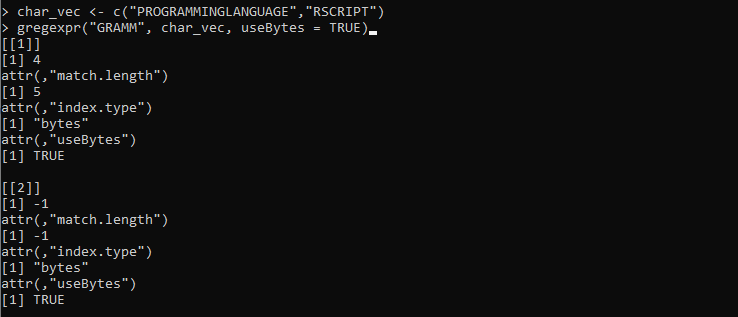
char_vec <- c('PROGRAMMINGLANGUAGE','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
כאן, אנו מגדירים את המשתנה 'char_vect' שבו המחרוזות מסופקות עם תווים שונים. לאחר מכן, אנו מגדירים את הפונקציה gregexpr() שלוקחת את תבנית המחרוזת 'GRAMM' כדי להתאים למחרוזות המאוחסנות ב-'char_vec'. לאחר מכן, אנו מגדירים את הפרמטר useBytes עם הערך 'TRUE'. פרמטר זה מציין שיש להשיג את ההתאמה בייט-byte ולא תו אחר תו.
הפלט הבא שאוחזר מהפונקציה gregexpr() מייצג את המדדים ואת האורך של שתי המחרוזות הווקטוריות:
דוגמה 3: ספירת סך התווים במחרוזת באמצעות הפונקציה Nchar() ב-R
שיטת nchar() שאנו מיישמים בהמשך מאפשרת לנו גם לקבוע כמה תווים יש במחרוזת:
Res <- nchar('ספור כל תו')הדפס (Res)
כאן אנו קוראים לשיטת nchar() המוגדרת בתוך המשתנה 'Res'. שיטת nchar() מסופקת עם מחרוזת התווים הארוכה אשר נספרת על ידי שיטת nchar() ומספקת את מספר תווי המונה במחרוזת שצוינה. לאחר מכן, אנו מעבירים את המשתנה 'Res' לשיטת print() כדי לראות את התוצאות של שיטת nchar() .
התוצאה מתקבלת בפלט הבא שמראה שהמחרוזת שצוינה מכילה 20 תווים:

דוגמה 4: חלץ את המחרוזת המשנה מהמחרוזת באמצעות הפונקציה Substring() ב-R
אנו משתמשים בשיטת substring() עם הארגומנטים 'start' ו-'stop' כדי לחלץ את המחרוזת הספציפית מהמחרוזת.
str <- substring('MORNING', 2, 4)print(str)
כאן, יש לנו משתנה 'str' שבו שיטת substring() נקראת. שיטת substring() לוקחת את המחרוזת 'MORNING' בתור הארגומנט הראשון ואת הערך של '2' בתור הארגומנט השני המציין שיש לחלץ את התו השני מהמחרוזת, והערך של הארגומנט '4' מציין ש יש לחלץ את הדמות הרביעית. שיטת substring() מחלצת את התווים מהמחרוזת בין המיקום שצוין.
הפלט הבא מציג את המחרוזת המשותפת שנמצאת בין המיקום השני והרביעי במחרוזת:

דוגמה 5: שרשרת את המחרוזת באמצעות הפונקציה Paste() ב-R
הפונקציה paste() ב-R משמשת גם למניפולציה של מחרוזת המשרשרת את המחרוזות שצוינו על ידי הפרדת המפרידים.
msg1 <- 'תוכן'msg2 <- 'כתיבה'
paste(msg1, msg2)
כאן, אנו מציינים את המחרוזות למשתנים 'msg1' ו-'msg2', בהתאמה. לאחר מכן, אנו משתמשים בשיטת paste() של R כדי לשרשר את המחרוזת המסופקת למחרוזת אחת. שיטת paste() לוקחת את משתנה המחרוזות כארגומנט ומחזירה את המחרוזת הבודדת עם רווח ברירת המחדל בין המחרוזות.
עם ביצוע שיטת paste(), הפלט מייצג את המחרוזת הבודדת עם הרווח בתוכה.

דוגמה 6: שנה את המחרוזת באמצעות הפונקציה Substring() ב-R
יתר על כן, אנו יכולים גם לעדכן את המחרוזת על ידי הוספת המחרוזת או כל תו לתוך המחרוזת באמצעות הפונקציה substring() באמצעות הסקריפט הבא:
str1 <- 'גיבורים'substring(str1, 5, 6) <- 'ic'
cat(' Modified String:', str1)
אנו מגדירים את המחרוזת 'Heroes' בתוך המשתנה 'str1'. לאחר מכן, אנו פורסים את שיטת substring() שבה צוין 'str1' יחד עם ערכי האינדקס 'start' ו-'stop' של המחרוזת. למתודה substring() מוקצית תת המחרוזת 'iz' אשר ממוקמת במיקום שצוין בפונקציה עבור המחרוזת הנתונה. לאחר מכן, אנו משתמשים בפונקציה cat() של R המייצגת את ערך המחרוזת המעודכנת.
הפלט שמציג את המחרוזת מתעדכן בחדש בשיטת substring ():

דוגמה 7: עצב את המחרוזת באמצעות הפונקציה Format() ב-R
עם זאת, פעולת מניפולציית המחרוזת ב-R כוללת גם עיצוב של המחרוזת בהתאם. לשם כך, אנו משתמשים בפונקציה format() שבה ניתן ליישר את המחרוזת ולהגדיר את הרוחב של המחרוזת הספציפית.
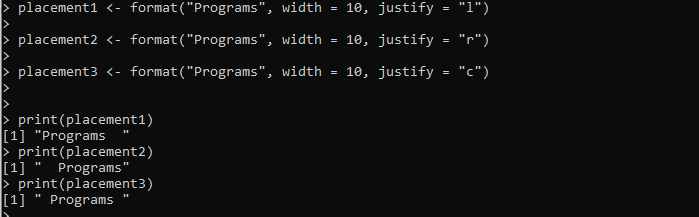
placement1 <- format('Programs', width = 10, justify = 'l')placement2 <- format('Programs', width = 10, justify = 'r')
placement3 <- format('Programs', width = 10, justify = 'c')
print(placement1)
print(placement2)
print(placement3)
כאן, אנו מגדירים את המשתנה 'placement1' המסופק בשיטת format(). אנו מעבירים את מחרוזת 'תוכניות' לעיצוב לשיטת format() . הרוחב מוגדר, והיישור של המחרוזת מוגדר לשמאל באמצעות הארגומנט 'הצדק'. באופן דומה, אנו יוצרים שני משתנים נוספים, 'placement2' ו-'placement2', ומיישמים את שיטת format() כדי לעצב את המחרוזת שסופקה בהתאם.
הפלט מציג שלושה סגנונות עיצוב עבור אותה מחרוזת בתמונה הבאה, כולל יישור שמאל, ימין ומרכז:
דוגמה 8: הפיכת המחרוזת לאותיות קטנות וגדולות ב-R
בנוסף, אנו יכולים גם להפוך את המחרוזת באותיות קטנות ובאותיות גדולות באמצעות הפונקציות tolower() ו-toupper() באופן הבא:
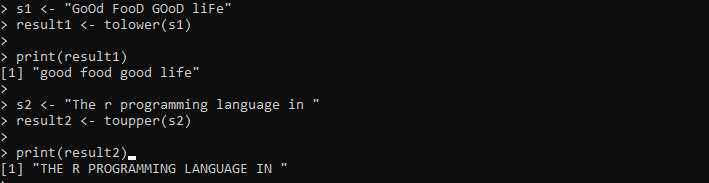
s1 <- 'אוכל טוב חיים טובים'תוצאה1 <- נמוך יותר(ים1)
הדפס (תוצאה1)
s2 <- 'שפת התכנות r ב'
תוצאה2 <- toper(s2)
הדפס (תוצאה2)
כאן אנו מספקים את המחרוזת המכילה את התווים הגדולים והקטנים. לאחר מכן, המחרוזת נשמרת במשתנה 's1'. לאחר מכן, אנו קוראים למתודה tolower() ומעבירים את המחרוזת 's1' בתוכה כדי להפוך את כל התווים בתוך המחרוזת באותיות קטנות. לאחר מכן, אנו מדפיסים את התוצאות של שיטת tolower() המאוחסנת במשתנה 'result1'. לאחר מכן, קבענו מחרוזת נוספת במשתנה 's2' שמכילה את כל התווים באותיות קטנות. אנו מיישמים את השיטה toupper() על מחרוזת 's2' זו כדי להפוך את המחרוזת הקיימת לאותיות רישיות.
הפלט מציג את שתי המחרוזות במקרה שצוין בתמונה הבאה:
סיכום
למדנו את הדרכים השונות לנהל ולנתח את המיתרים המכונה מניפולציה של מחרוזות. חילפנו את מיקום הדמות מהמחרוזת, שרשרנו את המחרוזות השונות והפכנו את המחרוזת למקרה שצוין. כמו כן, פירמטנו את המחרוזת, שינינו את המחרוזת, ומבצעים כאן פעולות שונות כדי לתפעל את המחרוזת.